딥러닝을 이용한 자연어처리 입문 # 6-1. 토픽 모델링
토픽 모델링 :
기계 학습이나 자연어 처리 분야에서 텍스트 본문의 숨겨진 의미 구조를 발견하기 위해 사용되는 텍스트 마이닝 기법
1) 잠재 의미 분석 (Latent Semantic Analysis, LSA)
- LSA : 토픽 모델링을 위한 최적화 알고리즘 x
- LDA : LSA의 단점을 보완한 최적화 알고리즘 o
- DTM or TF-IDF : 단어의 빈도 수를 이용한 수치화 방법 → 단어의 의미 고려하지 못함
⇒ 대안 = LSA : DTM의 의미를 이끌어내는 방법(잠재 의미 분석)
⇒ 특이값 분해(SVD)
특이값 분해(Singular Value Decomposition, SVD)
- A = m x n 행렬 → 3개의 행렬의 곱으로 분해
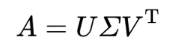

- 직교행렬 : 자신과 자신의 전치 행렬의 곱 또는 이를 반대로 곱한 결과가 단위행렬이 되는 행렬
- 대각행렬 : 주대각선을 제외한 곳의 원소가 모두 0인 행렬
- SVD로 나온 내각행렬의 대각 원소의 값을 행렬 A의 특이값
- 전치행렬 (Transposed Matrix)
- 원래의 행렬에서 행과 열을 바꾼 행렬
- 주 대각선을 축으로 반사 대칭을 해서 얻는 행렬
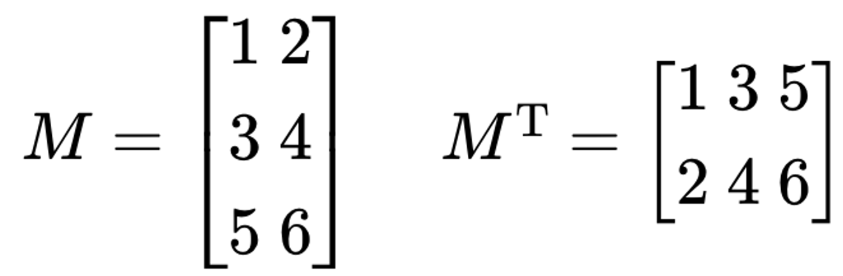
- 단위행렬 (Identify Matrix)
- 주대각선의 원소가 모두 1 & 나머지 원소는 모두 0인 정사각 행렬
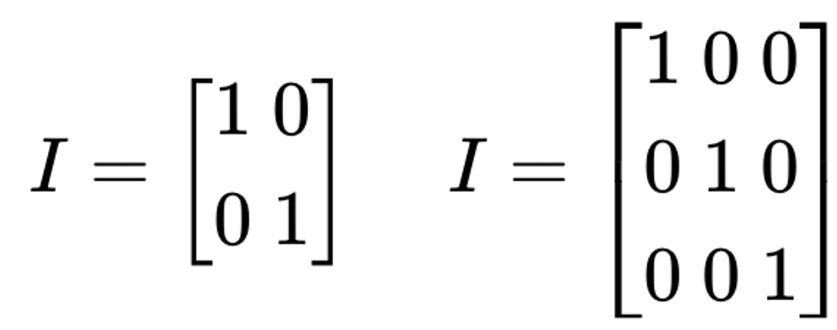
- 역행렬 (Inverse Matrix)
- 행렬 A와 어떤 행렬을 곱했을 때, 결과로 단위행렬이 나오면 어떤 행렬을 A의 역행렬
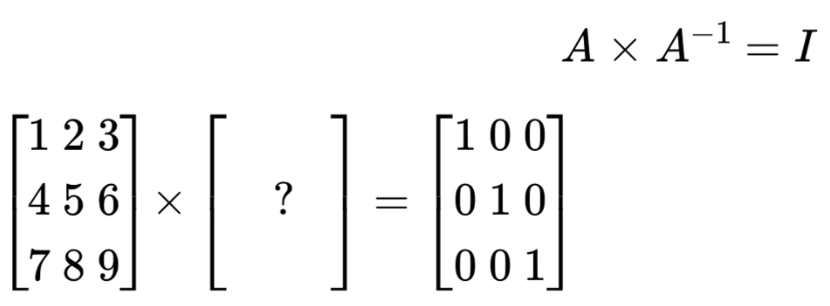
- 직교행렬 (Orthogonal Matrix)
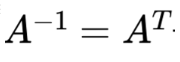
- 대각행렬 (Diagonal Matrix)
- 주대각선을 제외한 곳의 원소가 모두 0인 행렬
절단된 SVD (Truncated SVD)
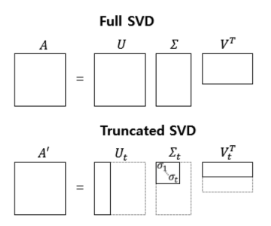
- U 행렬 : t열까지만 남김
- 대각행렬 : 상위값 t개만 남김
- V 행렬 : t열까지만 남김
- t = 토픽의 수를 반영한 하이퍼파라미터 값
- t 크면, 기존의 행렬 A로부터 다양한 의미 가질 수 있음
- t 작으면, 노이즈 제거 가능
- 장점)
- 데이터 차원 줄이면 계산 비용 낮아짐
- 불필요한 정보 삭제
잠재 의미 분석 (Latent Semantic Analysis, LSA)
DTM or TF-IDF 행렬에 절단된 SVD사용하여 차원 축소 → 잠재적인 의미 추출
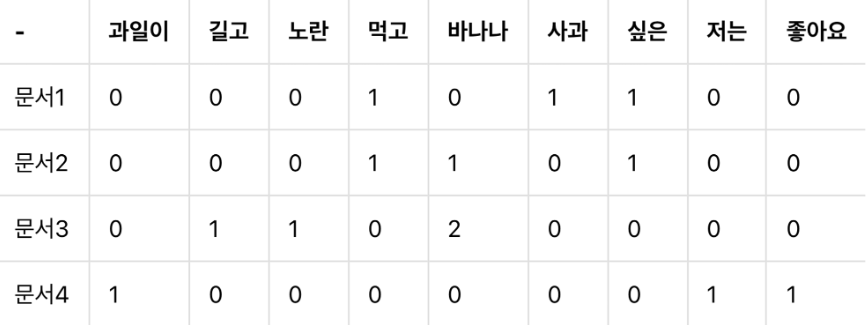
축소된 U : 4 x 2 → 문서의 개수 x 토픽의 수 t
- 각 행은 잠재 의미를 표현하기 위한 수치화 된 각각의 문서 벡터
- 축소된 VT : 2 x 9 → 토픽의 수 t x 단어의 개수
- 각 열은 잠재 의미를 표현하기 위해 수치화된 각각의 단어 벡터
LSA의 장단점 (Pros and Cons of LSA)
- 장점)
- 쉽고 빠르게 구현이 가능
- 단어의 잠재적인 의미를 이끌어 낼 수 있어 문서의 유사도 계산 등에서 좋은 성능
- 단점)
- 이미 계산된 LSA에 새로운 데이터를 추가하려고 하면 보통 처음부터 계산해야함 → 새로운 정보에 대해 업데이터 어려움
import numpy as np
a=np.array([~~~])
np.shape(a) #DTM 생성
# Full SVD
U, s, VT = np.linalg.svd(A,full_matrices = True)


반응형
'공부하는 습관을 들이자 > Deep Learning (NLP,LLM)' 카테고리의 다른 글
| [딥러닝 자연어처리] 7. 머신 러닝 개요 4) ~ 6) (0) | 2023.12.12 |
|---|---|
| [딥러닝 자연어처리] 7. 머신 러닝 개요 1) ~ 3) (0) | 2023.12.11 |
| [딥러닝 자연어처리] 5. 벡터의 유사도 (0) | 2023.12.06 |
| [딥러닝 자연어처리] 4. 카운트 기반의 단어 표현 (0) | 2023.12.05 |
| [딥러닝 자연어처리] 3. 언어모델 (Language Model) (0) | 2023.12.04 |



