딥러닝을 이용한 자연어처리 입문 # 5. 벡터의 유사도
벡터의 유사도란?
- 문장과 문서의 유사도
- 인간: 문서들 간에 동일한 단어가 얼마나 공통적으로 사용되었는지
- 기계: 문서의 단어들을 어떤 방법으로 수치화하여 표현했는지 (ex: DTM, Word2Vec), 문서간의 단어들의 차이를 어떤 방법으로 계산했는지 (ex: Euclidean distance, Cosine similarity)
1) 코사인 유사도
- 정의: 두 벡터간의 코사인 각도를 이용하여 구할 수 있는 벡터의 유사도

- 코사인 유사도는 -1에서 1사이의 값을 가짐
- 두 벡터의 방향이 동일할 경우: 1
- 두 벡터의 방향이 180도로 반대일 경우: -1
- 1에 가까울수록 유사도가 높다고 판단
2) 코사인 유사도 식

코사인 유사도의 장점 예시 >
문서1 : 저는 사과 좋아요
문서2 : 저는 바나나 좋아요
문서3 : 저는 바나나 좋아요 저는 바나나 좋아요
토큰화

import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(A,B):
return dot(A,B)/(norm(A)*norm(B))
doc1 = np.array([0,1,1,1])
doc2 = np.array([1,0,1,1])
doc3 = np.array([2,0,2,2])
print(cos_sim(doc1,doc2))
print(cos_sim(doc1,doc3))
print(cos_sim(doc2,doc3))
- 문서 2와 3은 벡터의 방향이 완전히 동일
- 단지 모든 단어의 빈도수가 1씩만 증가한 것
- 즉 한 문서 내의 모든 단어의 빈도수가 동일하게 증가하는 경우에는 기존의 문서와 코사인 유사도 값이 1이라는 것
시사점
- 코사인 유사도는 유사도 연산에서 길이의 영향을 받지 않음
- 벡터의 방향에 초점을 두므로 문서의 길이가 다른 상황에서도 비교적 공정한 비교를 할 수 있음
- 반면, 유클리디언 거리는 문서 2와 3을 다르게 판단함
여러가지 유사도 방법
1. 유클리드 거리 (Euclidean distance)
- 정의: 다차원 공간에서 두개의 점 p와q가 어떤 좌표를 가질 때, 두점 사이의 거리를 계산하는 것
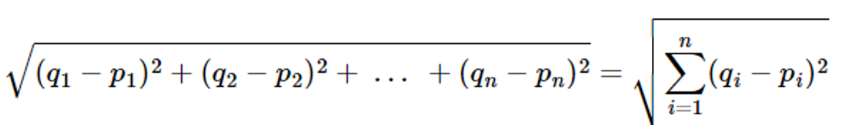
- 유클리드 거리의 값이 작을 수록 문서 간의 거리가 가장 가깝다는 것
- 거리가 가깝다 = 유사하다
- 그러므로, 문서 1과 문서 Q가 가장 유사함
import numpy as np
def dist(x,y):
return np.sqrt(np.sum((x-y)**2))
2. 자카드 유사도 (Jaccard similarity)
- 정의: A와B 집합이 있을때, 합집합에서 교집합의 비율을 구해주는 방법

- 0과 1사이의 값을 가짐
- 두 딥합이 동일하면 1의 값
- 공통 원소가 없으면 0
doc1 = "apple banana everyone like likey watch card holder"
doc2 = "apple banana coupon passport love you"
tokenized_doc1 = doc1.split()
tokenized_doc2 = doc2.split()
union = set(tokenized_doc1).union(set(tokenized_doc2))
intersection = set(tokenized_doc1).intersection(set(tokenized_doc2))
print('자카드 유사도 :' , len(intersection)/len(union))
3) 레벤슈타인 거리를 이용한 오타 정정
레벤슈타인 거리란?
- 문자열이 얼마나 비슷한 지를 나타내는 것으로 편집 거리라고도 부름
- 그렇다면 오타정정은 무슨 말일까?
- ex) “Find-alpha”를 “Finda-beta”로 잘못 검색했을때 레벤슈타인 거리를 사용하여 스스로 오타 정정을 해서 검색어를 정정
어떻게 동작할까?
- 예시) “가나다라”, “가마바라”


- 마지막 행 부분인 회색 부분이 최종 레벤슈타인 거리가 됨
- “가나다라”와 “가마바라”의 레벤슈타인 거리는 2
'공부하는 습관을 들이자 > Deep Learning (NLP,LLM)' 카테고리의 다른 글
| [딥러닝 자연어처리] 7. 머신 러닝 개요 1) ~ 3) (0) | 2023.12.11 |
|---|---|
| [딥러닝 자연어처리] 6-1. 토픽 모델링 (0) | 2023.12.08 |
| [딥러닝 자연어처리] 4. 카운트 기반의 단어 표현 (0) | 2023.12.05 |
| [딥러닝 자연어처리] 3. 언어모델 (Language Model) (0) | 2023.12.04 |
| [딥러닝 자연어처리] 2-2. 텍스트 전처리 (Text Preprocessing) (0) | 2023.12.01 |



