딥러닝을 이용한 자연어처리 입문 #3. 언어모델 (Language Model)
언어모델이란?
- 언어 모델(Languagel Model)이란 단어 시퀀스(문장)에 확률을 할당하는 모델
- 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일
자연어 처리에서 단어 시퀀스에 확률을 할당하는 일이 왜 필요할까?
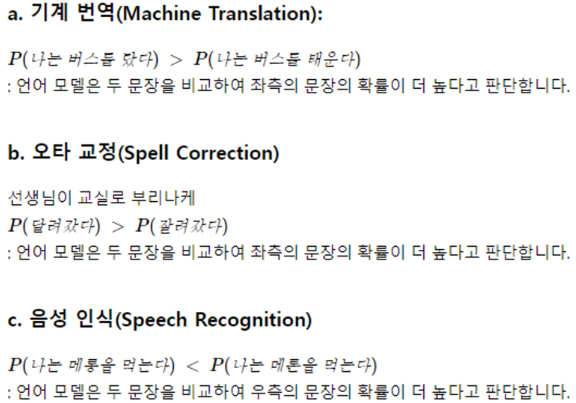
주어진 이전 단어들로부터 다음 단어 예측
- 단어 시퀀스의 확률
하나의 단어를 w, 단어 시퀀스을 대문자 W라고 한다면, n개의 단어가 등장하는 단어 시퀀스 W의 확률은 다음과 같다
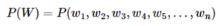
- 다음 단어 등장 확률
1개의 단어가 나열된 상태에서 n번째 단어의 확률
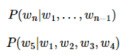
전체 단어 시퀀스 W의 확률은 모든 단어가 예측되고 나서야 알 수 있으므로 단어 시퀀스의 확률은 다음과 같음

N-gram 언어 모델
- 통계적 접근을 사용하고 있음
- 이전에 등장한 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법
- 이때 일부 단어를 몇 개 보느냐를 결정하는데 이것이 n-gram에서의 n이 가지는 의미
예를 들어서 문장 An adorable little boy is spreading smiles이 있을 때, 각 n에 대해서 n-gram을 전부 구해보면 다음과 같음

- 다음에 나올 단어를 예측하고 싶다고 할 때, n=4라고 한 4-gram을 이용한 언어 모델을 사용
- 이 경우, spreading 다음에 올 단어를 예측하는 것은 n-1에 해당되는 앞의 3개의 단어만을 고려

N-gram Language Model의 한계
- n을 크게 선택하면 실제 훈련 코퍼스에서 해당 n-gram을 카운트할 수 있는 확률은 적어지므로 희소 문제는 점점 심각해짐.
- n이 커질수록 코퍼스의 모든 n-gram에 대해서 카운트를 해야 하기 때문에 모델 사이즈가 커진다는 문제점도 있음
- n을 작게 선택하면 훈련 코퍼스에서 카운트는 잘 되겠지만 근사의 정확도는 현실의 확률분포와 멀어짐, 그렇기 때문에 적절한 n을 선택해야 함.
- n은 최대 5를 넘게 잡아서는 안 된다고 권장되고 있움.
언어 모델의 평가 방법(Evaluation metric) : PPL
- 펄플렉서티(perplexity)는 언어 모델을 평가하기 위한 내부 평가 지표
- PPL이 라고 표현
- 수치가 높으면 좋은 성능을 의미하는 것이 아니라, '낮을수록' 언어 모델의 성능이 좋다는 것을 의미
- PPL은 단어의 수로 정규화(normalization) 된 테스트 데이터에 대한 확률의 역수
- PPL을 최소화한다는 것은 문장의 확률을 최대화하는 것과 같음
- 문장 W의 길이가 N이라고 하였을 때의 PPL은 다음과 같음
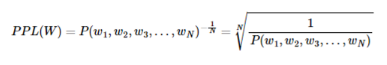
기존 언어 모델 Vs. 인공 신경망을 이용한 언어 모델

반응형
'공부하는 습관을 들이자 > Deep Learning (NLP,LLM)' 카테고리의 다른 글
| [딥러닝 자연어처리] 5. 벡터의 유사도 (0) | 2023.12.06 |
|---|---|
| [딥러닝 자연어처리] 4. 카운트 기반의 단어 표현 (0) | 2023.12.05 |
| [딥러닝 자연어처리] 2-2. 텍스트 전처리 (Text Preprocessing) (0) | 2023.12.01 |
| [딥러닝 자연어처리] 2-1. 텍스트 전처리 (Text Preprocessing) (0) | 2023.11.30 |
| [딥러닝 자연어처리] 1. 자연어처리란? (0) | 2023.11.29 |



