딥러닝을 이용한 자연어처리 입문 #4. 카운트 기반의 단어 표현
1. 다양한 단어의 표현 방법
1. 단어의 표현 방법
- 국소 표현 - 단어 자체만 보고, 특정값을 맴핑해 단어 표현하는 방법
- 분산 표현 - 주변을 참고해서 단어 표현하는 방법
- ex) puppy, cute, lovely란 단어가 있을 때, 숫자를 mapping → 국소 표현 방법
- ↔ 분산 표현 방법 = 단어 표현 위해 주변 단어 참고
- puppy란 단어 근처에 cute, lovely가 나오게 되면 → puppy를 이런 단어로 정의하도록
- 분산 표현은 단어의 뉘앙스를 이해, 표현하도록 함
- 국소 표현 ⇒ 이산 표현, 분산 표현 ⇒ 연속 표현 (분리 방법과 관련있음)
2. 단어 표현의 카테고리화
- 뒤에 나오는 Bag of Words ⇒ 국소 표현에 속해. 빈도수를 count해 단어를 수치화
2. Bag of Words
- 빈도수 기반의 단어 표현 방법
- 각 단어에 정수 인덱스 부여
- 각 인덱스 위체 단어 토큰 등장 횟수를 기록한 벡터를 만듬.
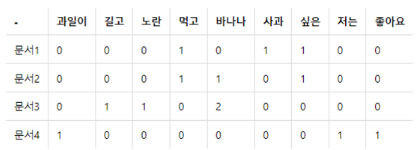
3. 문서 단어 행렬
문서 단어 행렬(DTM) : BoW 표현 방법을 그대로 가져와서 이를 다른 문서들의 BoW와 결합해 표현하는 방식
1) 문서 단어 행렬의 표기법

2) DTM의 한계
- 희소 표현
- One-Hot encoding과 유사한 단점
- 값이 있는 벡터 차원을 제외하고 나머지를 모두 0으로 설정하기에 공간적 낭비, 계산 리소스를 증가시킬 수 있음
- DTM또한 동일한 단점 보유.
- 낭비되는 데이터 제거 위한 전처리 과정은 매우 중요함
- 단순 빈도 수 기반 접근
- 어떤 단어가 중요한 지를 파악하지 못하고, 그냥 1차원적으로 무조건 빈도만 多 → 중요 단어로 인식.
- 실제 그렇지 않는 단어 또한 중요 단어로 인식하는 경우가 생김
- 이에 따른 해결방법으로 TF-IDF를 사용함
TF-IDF
- DTM의 각 단어에 대한 중요 정도를 가중치 주는 방법 - DTM 先 제작, 가중치 부여.
- 문사 유사도, 검색에서 검색 결과의 중요도 정하는 작업, 특정 단어의 중요도 구하는 작업에 이용.
- TF-IDF = TF * IDF, d = 문서, t = 단어, n = 문서 총 개수
i) TF(d,t) = 특정 문서 d에서 특정 단어 t의 등장 횟수 = DTM에서 각 단어 들이 가진 값들.
ii) DF(t) = 특정 단어 t가 등장한 문서 수 ⇒ 오직 문서의 수에만 포커스하는 방식.
iii) IDF(d,t) = DF(t)에 반비례하는 수
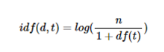
- df역수, log화는 n이 증가하면 idf값 증가하기 때문에 억제를 하지 못함
- 분모에 df(t)+1인 이유는 분모 0인 것을 막아줌
- TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단됨


pip install tensorflow
import tensorflow as tf
pip install gensim
#gensim은 토픽 모델링과 자연어 처리를 수행할 수 있게 해주는 오픈 소스 라이브러리
pip install konlpy
import konlpy
import tweepy
import pandas as pd
import pandas_profiling
data = pd.read_csv('spam.csv', encoding = 'latin1')
data.head()
!pip show pandas_profiling
pr = data.profile_report()
data.profile_report() #프로파일링 결과를 바라볼 수 있는 것.
#여기서 결측치가 매우 많은 것으로 확인됨.토큰화
from nltk.tokenize import word_tokenize
print(word_tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
#word_tokenize라는 실제 안에 있는 패키지의 정보를 가지고 아래 문장을 토큰화 시킨 것.
# ['Do', "n't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr.', 'Jone', "'s", 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']
from tensorflow.keras.preprocessing.text import text_to_word_sequence
print(text_to_word_sequence("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
#상대적으로 keras의 방법은 소문자를 그대로 유지하고, "\''"등을 그대로 잘 유지해주는 경우가 있음.
# ["don't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', 'mr', "jone's", 'orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "Starting a home-based restaurant may be an ideal. it doesn't have a food chain or restaurant of their own."
print(tokenizer.tokenize(text))
#Penn Treebank Tokenization의 규칙은
#1. 하이픈으로 구성된 단어는 하나로 유지.
#2. donesn't와 같이 \'로 같이 '접어 '가는 단어는 분리.
# ['Starting', 'a', 'home-based', 'restaurant', 'may', 'be', 'an', 'ideal.', 'it', 'does', "n't", 'have', 'a', 'food', 'chain', 'or', 'restaurant', 'of', 'their', 'own', '.']문장 토큰화 by KSS
pip install kss
import kss
text = '딥 러닝 자연어 처리가 재미있기는 합니다. 그런데 문제는 영어보다 한국어로 할 때 너무 어렵습니다. 이제 해보면 알걸요?'
print(kss.split_sentences(text))
from konlpy.tag import Kkma
kkma = Kkma()
print(kkma.morphs("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print([lemmatizer.lemmatize(w) for w in words])
#이렇게 표제어 추출한 것은 상대적으로 원래 단어의 형태가 적절히 보존되고 있다는 것이 확인이 가능해. -> but 문제나는 건 원래 품사를 알고 있어야 정확한 결과 얻을 수 있어.
['policy', 'doing', 'organization', 'have', 'going', 'love', 'life', 'fly', 'dy', 'watched', 'ha', 'starting']
lemmatizer.lemmatize('dies', 'v') #이런 식으로 품사같이 알려주면 잘 나옴.
'die'
from nltk.corpus import stopwords
stopwords.words('english')[:10] #필요없는 단어들 자동으로 저장되어 있는 것들
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example = "Family is not an important thing. It's everything."
stop_words = set(stopwords.words('english')) #여기에 stopwords에 포함되어 있는 것들 집합으로 포함시켜주는 것.
word_tokens = word_tokenize(example) #example을 word_token으로 나눠주고
result = []
for w in word_tokens:
if w not in stop_words:
result.append(w)
print(word_tokens)
print(result)
['Family', 'is', 'not', 'an', 'important', 'thing', '.', 'It', "'s", 'everything', '.']
['Family', 'important', 'thing', '.', 'It', "'s", 'everything', '.']
example = "고기를 아무렇게나 구우려고 하면 안 돼. 고기라고 다 같은 게 아니거든. 예컨대 삼겹살을 구울 때는 중요한 게 있지."
stop_words = "아무거나 아무렇게나 어찌하든지 같다 비슷하다 예컨대 이럴정도로 하면 아니거든"
stop_words = set(stop_words.split(' ')) #사실상 직접 stop_words사전을 만들어서 해당되는 것들에 대해서 제외해주겠다고 표현해준 것.
word_tokens = word_tokenize(example)
result = [word for word in word_tokens if not word in stop_words]
print(word_tokens)
print(result)
['고기를', '아무렇게나', '구우려고', '하면', '안', '돼', '.', '고기라고', '다', '같은', '게', '아니거든', '.', '예컨대', '삼겹살을', '구울', '때는', '중요한', '게', '있지', '.']
['고기를', '구우려고', '안', '돼', '.', '고기라고', '다', '같은', '게', '.', '삼겹살을', '구울', '때는', '중요한', '게', '있지', '.']정규표현식
import re
r = re.compile('a.c')
r.search('kkk')
r.search('abc')
<re.Match object; span=(0, 3), match='abc'>
#?는 앞에 있거나 없는 케이스에 대해서 포함시켜주는 것
r = re.compile('ab?c')
r.search('ac')반응형
'공부하는 습관을 들이자 > Deep Learning (NLP,LLM)' 카테고리의 다른 글
| [딥러닝 자연어처리] 6-1. 토픽 모델링 (0) | 2023.12.08 |
|---|---|
| [딥러닝 자연어처리] 5. 벡터의 유사도 (0) | 2023.12.06 |
| [딥러닝 자연어처리] 3. 언어모델 (Language Model) (0) | 2023.12.04 |
| [딥러닝 자연어처리] 2-2. 텍스트 전처리 (Text Preprocessing) (0) | 2023.12.01 |
| [딥러닝 자연어처리] 2-1. 텍스트 전처리 (Text Preprocessing) (0) | 2023.11.30 |



