딥러닝을 이용한 자연어처리 입문 #2-2. 텍스트 전처리 (Text Preprocessing)
06) 정수 인코딩(Integer Encoding)
- 컴퓨터는 텍스트보다는 숫자를 더 잘 처리할 수 있음. 특정 단어들과 매핑되는 고유한 정수, 인덱스를 부여하는 것
1. 정수 인코딩
- Dictionary 사용하기
from nltk.tokenize import sent_tokenize
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
raw_text = "A barber is a person. a barber is good person. a barber is huge person. he Knew A Secret! The Secret He Kept is huge secret. Huge secret. His barber kept his word. a barber kept his word. His barber kept his secret. But keeping and keeping such a huge secret to himself was driving the barber crazy. the barber went up a huge mountain."- 문장 토큰화
sentences = sent_tokenize(raw_text)
print(sentences)
['A barber is a person.', 'a barber is good person.', 'a barber is huge person.', 'he Knew A Secret!', 'The Secret He Kept is huge secret.', 'Huge secret.', 'His barber kept his word.', 'a barber kept his word.', 'His barber kept his secret.', 'But keeping and keeping such a huge secret to himself was driving the barber crazy.', 'the barber went up a huge mountain.']- 단어토큰화
vocab = {}
preprocessed_sentences = []
stop_words = set(stopwords.words('english'))
for sentence in sentences:
# 단어 토큰화
tokenized_sentence = word_tokenize(sentence)
result = []
for word in tokenized_sentence:
word = word.lower() # 모든 단어를 소문자화하여 단어의 개수를 줄인다.
if word not in stop_words: # 단어 토큰화 된 결과에 대해서 불용어를 제거한다.
if len(word) > 2: # 단어 길이가 2이하인 경우에 대하여 추가로 단어를 제거한다.
result.append(word)
if word not in vocab:
vocab[word] = 0
vocab[word] += 1
preprocessed_sentences.append(result)
print(preprocessed_sentences)
[['barber', 'person'], ['barber', 'good', 'person'], ['barber', 'huge', 'person'], ['knew', 'secret'], ['secret', 'kept', 'huge', 'secret'], ['huge', 'secret'], ['barber', 'kept', 'word'], ['barber', 'kept', 'word'], ['barber', 'kept', 'secret'], ['keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy'], ['barber', 'went', 'huge', 'mountain']]- 각 단어에 대한 빈도수
print(vocab)
#{'barber': 8, 'person': 3, 'good': 1, 'huge': 5, 'knew': 1, 'secret': 6, 'kept': 4, 'word': 2, 'keeping': 2, 'driving': 1, 'crazy': 1, 'went': 1, 'mountain': 1}- 빈도수 높은 순서대로 정렬
vocab_sorted = sorted(vocab.items(), key = lambda x:x[1], reverse = True)
print(vocab_sorted)
#[('barber', 8), ('secret', 6), ('huge', 5), ('kept', 4), ('person', 3), ('word', 2), ('keeping', 2), ('good', 1), ('knew', 1), ('driving', 1), ('crazy', 1), ('went', 1), ('mountain', 1)]- 높은 빈도수를 가진 단어일수록 낮은 정수 인덱스 부여
word_to_index = {}
i = 0
for (word, frequency) in vocab_sorted :
if frequency > 1 : # 빈도수가 작은 단어는 제외.
i = i + 1
word_to_index[word] = i
print(word_to_index)
#{'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'word': 6, 'keeping': 7}- 빈도수 상위 5개 단어만 사용
vocab_size = 5
words_frequency = [word for word, index in word_to_index.items() if index >= vocab_size + 1] # 인덱스가 5 초과인 단어 제거
for w in words_frequency:
del word_to_index[w] # 해당 단어에 대한 인덱스 정보를 삭제
print(word_to_index)
#{'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5}
- 단어 집합에 존재하지 않는 단어(OOV)를 추가하고 인덱스 부여
word_to_index['OOV'] = len(word_to_index) + 1
print(word_to_index)
#{'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'OOV': 6}- word_to_index를 사용해 sentences의 모든 단어들을 매핑되는 정수로 인코딩
encoded_sentences = []
for sentence in preprocessed_sentences:
encoded_sentence = []
for word in sentence:
try:
encoded_sentence.append(word_to_index[word])
except KeyError:
encoded_sentence.append(word_to_index['OOV'])
encoded_sentences.append(encoded_sentence)
print(encoded_sentences)
#[[1, 5], [1, 6, 5], [1, 3, 5], [6, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [6, 6, 3, 2, 6, 1, 6], [1, 6, 3, 6]]07) 패딩(Padding)
- 자연어 처리를 하다보면 각 문장은 서로 길이가 다를 수 있음.
- 기계는 길이가 전부 동일한 문서들에 대해서는 하나의 행렬로 보고, 한꺼번에 묶어서 처리할 수 있음.
- 다시 말해 병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업이 필요할 때가 있음
1. Numpy로 패딩하기
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
preprocessed_sentences = [['barber', 'person'], ['barber', 'good', 'person'], ['barber', 'huge', 'person'], ['knew', 'secret'], ['secret', 'kept', 'huge', 'secret'], ['huge', 'secret'], ['barber', 'kept', 'word'], ['barber', 'kept', 'word'], ['barber', 'kept', 'secret'], ['keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy'], ['barber', 'went', 'huge', 'mountain']]- 정수 인코딩 수행
tokenizer = Tokenizer()
# fit_on_texts()안에 코퍼스를 입력으로 하면 빈도수를 기준으로 단어 집합을 생성.
tokenizer.fit_on_texts(preprocessed_sentences)
encoded = tokenizer.texts_to_sequences(preprocessed_sentences)
print(encoded)
#[[1, 5], [1, 8, 5], [1, 3, 5], [9, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [7, 7, 3, 2, 10, 1, 11], [1, 12, 3, 13]]- 모두 동일한 길이로 맞춰주기 위해 이 중에서 가장 길이가 긴 문장의 길이 계산
max_len = max(len(item) for item in encoded)
print(max_len)
#7for sentence in encoded: # 각 문장에 대해서
while len(sentence) < max_len: # max_len보다 작으면
sentence.append(0)
padded_np = np.array(encoded)
padded_np
#array([[ 1, 5, 0, 0, 0, 0, 0],
# [ 1, 8, 5, 0, 0, 0, 0],
# [ 1, 3, 5, 0, 0, 0, 0],
# [ 9, 2, 0, 0, 0, 0, 0],
# [ 2, 4, 3, 2, 0, 0, 0],
# [ 3, 2, 0, 0, 0, 0, 0],
# [ 1, 4, 6, 0, 0, 0, 0],
# [ 1, 4, 6, 0, 0, 0, 0],
# [ 1, 4, 2, 0, 0, 0, 0],
# [ 7, 7, 3, 2, 10, 1, 11],
# [ 1, 12, 3, 13, 0, 0, 0]]) 제로패딩08) 원-핫 인코딩(One-Hot Encoding)
- 단어 집합의 크기를 벡터의 차원, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
# 코엔엘파이의 Okt 형태소 분석기를 통해서 우선 문장에 대해서 토큰화 수행
from konlpy.tag import Okt
okt = Okt()
token = okt.morphs("나는 자연어 처리를 배운다")
print(token)
#['나', '는', '자연어', '처리', '를', '배운다']
# 토큰에 대해 인덱스 부여
word2index = {}
for voca in token:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
print(word2index)
def one_hot_encoding(word, word2index):
one_hot_vector = [0]*(len(word2index))
index = word2index[word]
one_hot_vector[index] = 1
return one_hot_vector
one_hot_encoding("자연어", word2index)
#[0, 0, 1, 0, 0, 0]케라스를 이용해서도 원-핫 인코딩이 가능함
원-핫 인코딩(One-Hot Encoding)의 한계
- 단어의 개수가 늘어날수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어남
- 단어의 유사도를 표현하지 못함
09) 데이터의 분리(Splitting Data)
10) 한국어 전처리 패키지
- PyKoSpacing
!pip install git+https://github.com/haven-jeon/PyKoSpacing.git
sent = '김철수는 극중 두 인격의 사나이 이광수 역을 맡았다. 철수는 한국 유일의 태권도 전승자를 가리는 결전의 날을 앞두고 10년간 함께 훈련한 사형인 유연재(김광수 분)를 찾으러 속세로 내려온 인물이다.'
new_sent = sent.replace(" ", '') # 띄어쓰기가 없는 문장 임의로 만들기
print(new_sent)
#김철수는극중두인격의사나이이광수역을맡았다.철수는한국유일의태권도전승자를가리는결전의날을앞두고10년간함께훈련한사형인유연재(김광수분)를찾으러속세로내려온인물이다.
from pykospacing import Spacing
spacing = Spacing()
kospacing_sent = spacing(new_sent)
print(sent)
print(kospacing_sent)
- Py-Hanspell
- 네이버 한글 맞춤법 검사기를 바탕으로 만들어진 패키지
!pip install git+https://github.com/ssut/py-hanspell.git
from hanspell import spell_checker
sent = "맞춤법 틀리면 외 않되? 쓰고싶은대로쓰면돼지 "
spelled_sent = spell_checker.check(sent)
hanspell_sent = spelled_sent.checked
print(hanspell_sent)
#맞춤법 틀리면 왜 안돼? 쓰고 싶은 대로 쓰면 되지
spelled_sent = spell_checker.check(new_sent)
hanspell_sent = spelled_sent.checked
print(hanspell_sent)
print(kospacing_sent) # 앞서 사용한 kospacing 패키지에서 얻은 결과
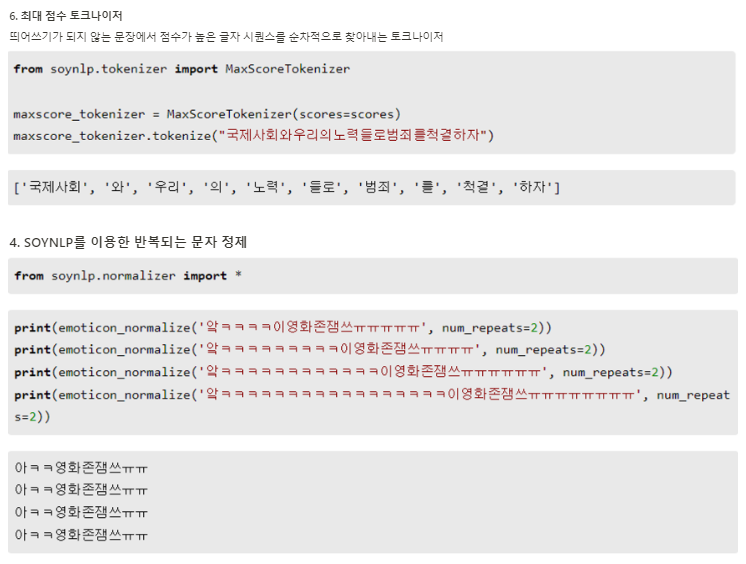
- SOYNLP를 이용한 단어 토큰화
- 텍스트 데이터에서 특정 문자 시퀀스가 함께 자주 등장하는 빈도가 높고, 앞 뒤로 조사 또는 완전히 다른 단어가 등장하는 것을 고려해서 해당 문자 시퀀스를 형태소라고 판단하는 단어 토크나이저
!pip install soynlp
import urllib.request
from soynlp import DoublespaceLineCorpus
from soynlp.word import WordExtractor
# 훈련 데이터를 다수의 문서로 분리
corpus = DoublespaceLineCorpus("2016-10-20.txt")
len(corpus)
i = 0
for document in corpus:
if len(document) > 0:
print(document)
i = i+1
if i == 3:
break
word_extractor = WordExtractor()
word_extractor.train(corpus)
word_score_table = word_extractor.extract()- SOYNLP의 응집 확률(cohesion probability)
- 응집확률: 내부 문자열이 얼마나 응집하여 자주 등장하는지를 판단하는 척도
- 이 값이 높을수록 전체 코퍼스에서 이 문자열 시퀀스는 하나의 단어로 등장할 가능성이 높음


- SOYNLP의 브랜칭 엔트로피(branching entropy)
주어진 문자열에서 얼마나 다음 문자가 등장할 수 있는지를 판단하는 척도

- SOYNLP의 L tokenizer
- 한국어는 띄어쓰기 단위로 나눈 어절 토큰은 주로 L토큰 + R토큰의 형식을 가질 때가 많음

반응형
'공부하는 습관을 들이자 > Deep Learning (NLP,LLM)' 카테고리의 다른 글
| [딥러닝 자연어처리] 5. 벡터의 유사도 (0) | 2023.12.06 |
|---|---|
| [딥러닝 자연어처리] 4. 카운트 기반의 단어 표현 (0) | 2023.12.05 |
| [딥러닝 자연어처리] 3. 언어모델 (Language Model) (0) | 2023.12.04 |
| [딥러닝 자연어처리] 2-1. 텍스트 전처리 (Text Preprocessing) (0) | 2023.11.30 |
| [딥러닝 자연어처리] 1. 자연어처리란? (0) | 2023.11.29 |



