
안녕하세요!
브라이틱스 서포터즈 3기 서영석입니다 😊
6주의 개인 분석 프로젝트 중
3주차 포스팅을 들고 왔습니다!
벌써 반이 지났네요 ㅎㅎ
저는 지금 벨기에 카페에 앉아
뚝딱뚝딱 브라이틱스를 만지고 있네요 🇧🇪☕️
역시 노코드 AI 오픈소스의 대명사인 브라이틱스...
더욱더 간지가 납니다 키키키
유럽여행 중에 브라이틱스를 경험하는 것도
하나의 좋은 경험인 것 같습니다 😉

숙소에서도 하는 브라이틱스
0. 재밌는 유튜브 영상 공유!
포스팅 전에!
하나 재밌는 사실 알려드릴게요 하핳
부끄럽긴 하지만
저희 영상이 드디어 올라왔습니다!
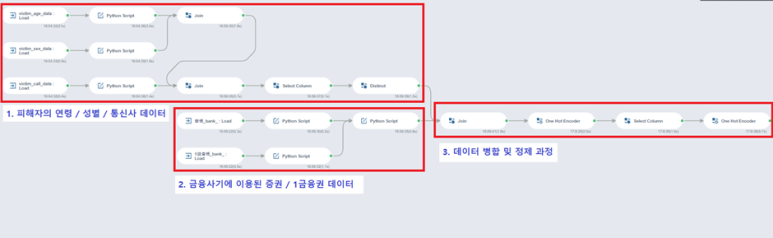
그렇다면 이제 프로젝트를 진행해보겠습니다!
이번 포스팅에는
2. 금융사기에 이용된
증권 / 1금융권 데이터에 대한 설명과
3. 데이터 병합 및 정제 과정에 대해
설명드리도록 하겠습니다.
바로 시작해보겠습니다 고고~!!
1. 금융사기에 이용된 증권 / 1금융권 데이터
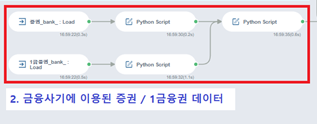
바로 위 프로세스 부분에 해당하는 내용입니다 😊
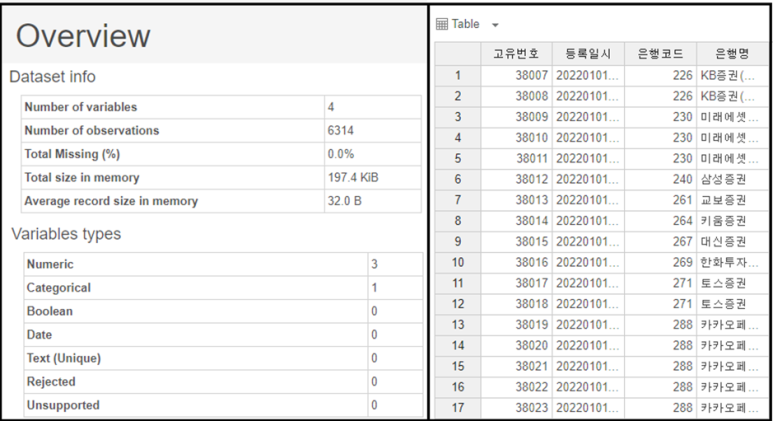
<금융사기에 이용된 증권 데이터>
보시면 컬럼수가 4개,
총 데이터가 6314개임을 볼 수 있습니다.
아마 1금융권이 아닌 증권데이터이기에
별로 개수가 없는 것 같습니다. ㅎㅎ
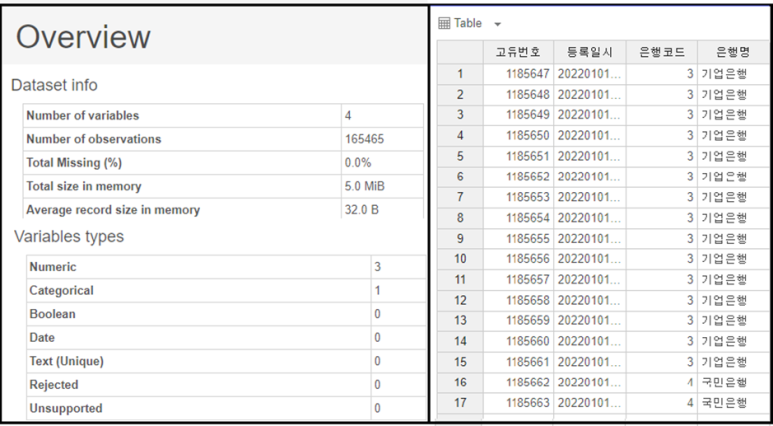
<금융사기에 이용된 1금융권 데이터>
컬럼 수는 4개이며,
위와 다르게 165,465개의
데이터가 존재함을 볼 수 있습니다.
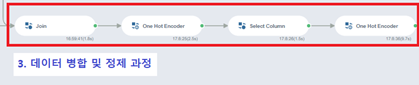
2. python script ( key & 병합)
이 두가지의 데이터를 병합하기 전,
피해자의 연령 / 성별 / 통신사 데이터와
마찬가지로
python script를 통해 key를 만들었습니다.
또한 증권 / 1금융권 데이터를 단순 병합하기 위해
python script를 하나 더 만들었어요!
3. Join & Distinct
Join -> Distinct 과정을 통해
총 114,138개의
rows를 가진 데이터로
통합하였습니다.
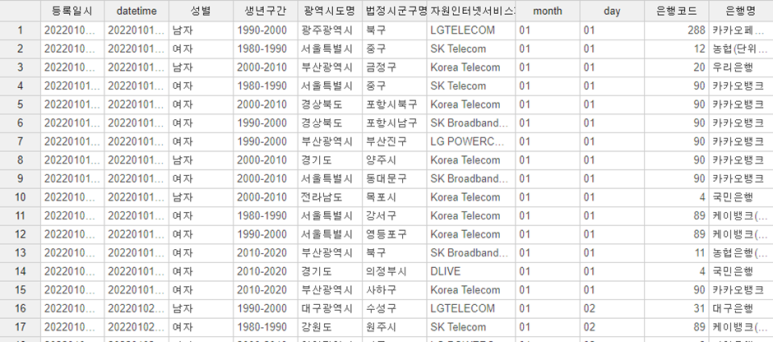
그리하여 통합된 데이터프레임입니다.
앞으로 성별, 생년구간 광역시도명이랑
법정시군구명, 자원인터넷서비스 등의
수치형 변환이 필요한데요.
한번 보시죠~!! 헤헤
문자열로 된 컬럼을 수치형으로 변환하는데 있어
저는 ‘Label Encoder’와 ‘One Hot Encoder’를 사용했습니다.
4. Label Encoder vs One Hot Encoder
그렇다면.. 둘의 차이점이 무엇일까요?
Label Encoder는 여러 변수가 있더라도 일련의 숫자로 하여금 하나의 Column 내에서 처리합니다.
One Hot Encoder는 여러 변수를 그 변수에 대한 Column들을 일일이 생성하여 처리합니다.
예를 들어 Column명이 '이름'이고, 김브스, 서브스, 최브스로 세 가지의 범주형 범수를 처리한다고 하면,
Label Encoder는 이름_index로 Column을 만들고,
김브스를 0, 서브스를 1, 최브스를 2로 분류합니다.
One Hot Encoder는 Column명을 아예 이름_0, 이름_1, 이름_2 로 하여
각각 김브스와 서브스, 최브스를 분류하여
이에 해당하면 1, 해당하지 않는다면 0으로 column을 채우는 방식입니다.
저희는 분류 모델의 경우이기에 둘 다 사용하되,
변수가 적은 성별 , 생년구간은 Label Encoder로,
변수가 많은 법정시군구명과 자원인터넷서비스의 경우 One-Hot Encoder를 사용하였습니다.
5. Label Encoder
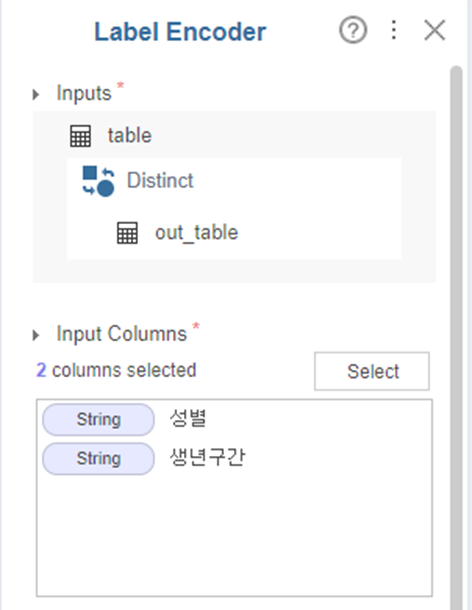
Label Encoder를 사용하여 변환을 하였는데요!
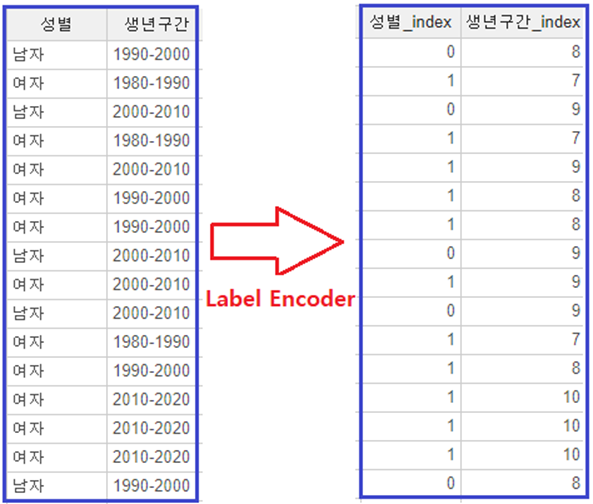
이처럼 남자는 0, 여자는 1로 변환을
90년대생을 8, 80년대생을 7 등으로
순서대로 변환을 하였습니다!
6. One Hot Encoder

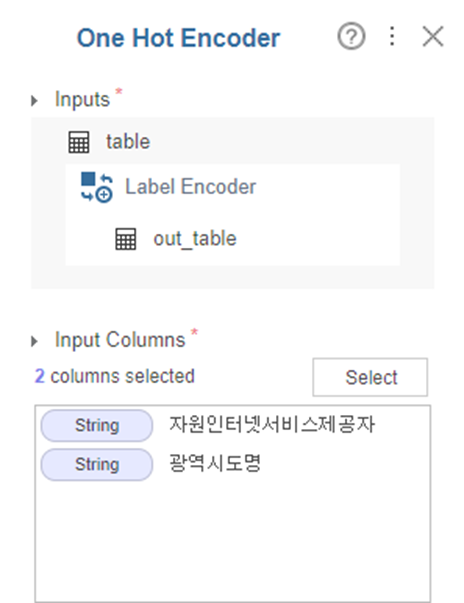
통신사와 관련된 자원인터넷서비스제공자와
큰 지역범위인 ‘광역시도명’을
One Hot Encoder를 통해 변수를 만들었습니다.
이렇게 진행하여 모델링 전까지의
데이터를 만들었는데요!
데이터 변수와 전반적인 EDA 분석에 대한 설명은 4주차에,
모델링의 전반적인 내용은 5주차에 진행하고자 합니다!
그렇다면 다음주에 금융사기에 이용된 피해자들의 유형을 파악하여 분석을 진행하도록 하겠습니다.
제 포스팅을 봐주셔서 감사합니다 :)
본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.



