
안녕하세요.
삼성 SDS 브라이틱스 서포터즈 3기 서영석입니다.
이번에는 개인 분석 프로젝트가 시작한 지 벌써 5주차에 들어섰는데요.
지난번 프로젝트에 이어서 이번에는 모델링을 구축해보려고 합니다.
그 전에!!
브라이틱스 홍보를 위해 한가지 달라진 점을 말씀드리려고 합니다 :)
브라이틱스는 총 세가지의 버전으로
'상용화 버전의 Brightics AI' , 일반적인 분석을 위해 사용하는
'Brightics Studio' 그리고 '중/고등 교육용 Brightics Education' 버전으로 나뉩니다.
이번에는 기존 Brightics Studio 와 Education을 통합된 통합 버전이 출시되었습니다!
새롭게 출시된 통합 버전은
데이터 분석을 위한 200개 이상의 함수를 제공할 뿐만 아니라
함수 즐겨찾기 및 국/영문 언어 설정을 지원하여 사용자의 편의성을 증대시켰습니다.
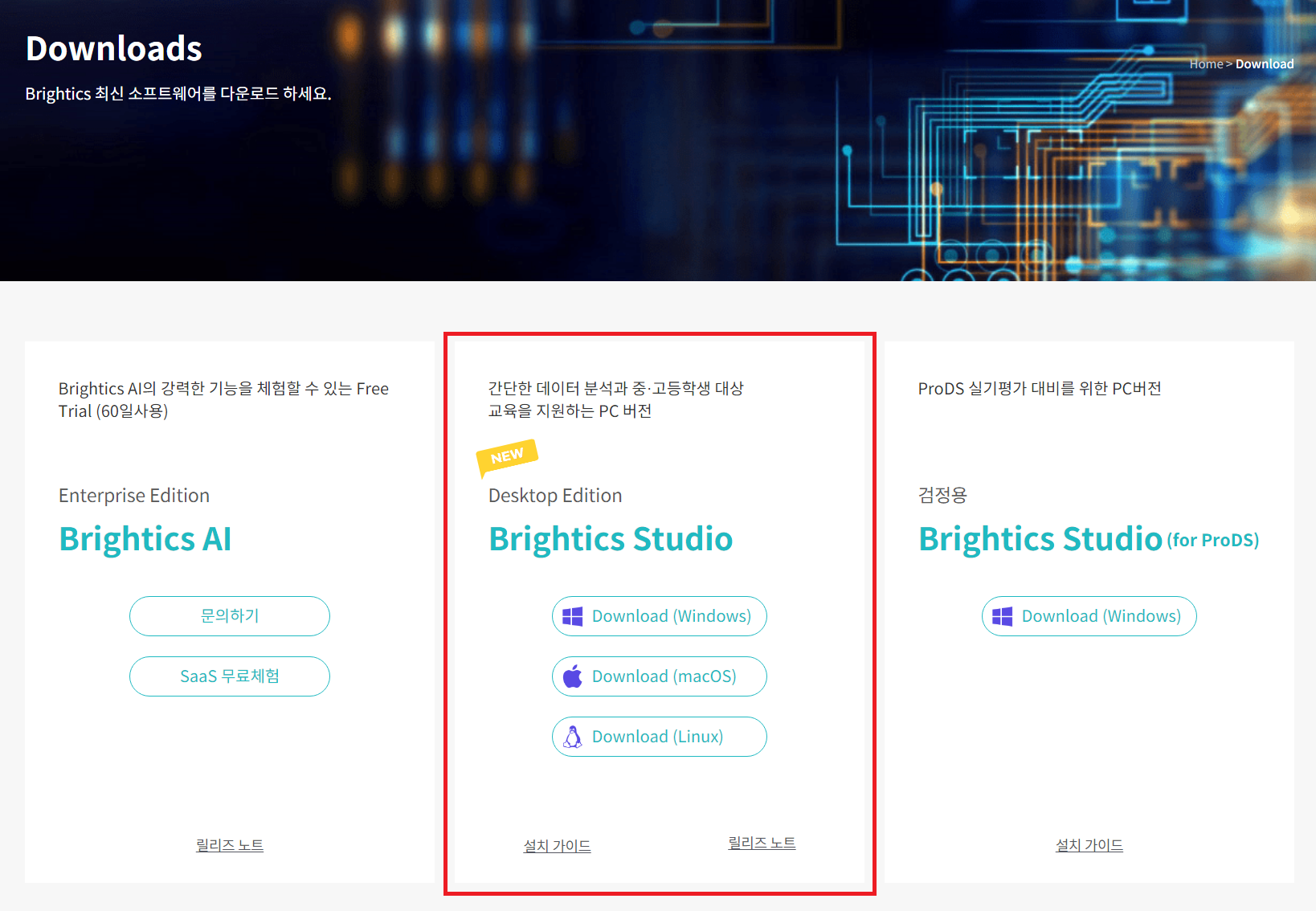
통합된 Brightics Studio을 사용해 보세요!! ㅎ_ㅎ
Brightics AI
www.brightics.ai
* 통합 버전 설치 시, 기존 Studio는 삭제 후 설치해야합니다.
(이전 포스팅에도 설명했지만.. 작업중인 JSON 파일의 백업은 필수입니다!!)
이제 개인 프로젝트를 시작해볼까요??
가보자악!!
근데 궁금한 것이 있어..!!
현재 Y변수가 은행명으로 되어 있는데,
이를 통해 얻고자 하는 분석적 목표가 무엇인지에 대한 피드백이 있었습니다.
Y변수를 은행명으로 잡은 가장 중요한 이유는
기업적으로 바라봤을 때,
각 은행별로의 보안과 금융사기에 대한 예방을 철저히 하기 위함입니다.
예를 들어, 20대의 남자들의 경우 'XX뱅크'로 분류되는 경우가 많다면
'XX뱅크'는 20대의 남자들에게 보안을 높일 수 있겠죠?
혹은 금융 사기와 관련된 보험을 제시한다거나 다양한 상품들을 제공할 수 있을 것 같습니다.
소비자 측면으로 바라봤을 때,
자신이 a뱅크, b뱅크, c뱅크를 사용중인데,
이 중 자신과 비슷한 유형의 사람들이 어느 금융에서 많이 취약했는지를 알려줌으로써
개인적인 보안과 점검을 한번 더 할 수 있도록 하기 위함입니다.
퍼센트나 건수 등 수치적으로 알려주며
자신이 어느 금융에서 조심해야할지를 알려준다고 생각하면 될 것 같습니다.
사실상 분류의 목적과는 다를 수도 있으나,
분류를 함으로서 얻게되는 점은
이 두 가지 측면 이외에도
금융사기의 현황에 있어 많이 쓰이는 금융권을
알 수 있는 등의 정보들을 얻을 수 있습니다.
전처리 과정 중 변경 사항

<Label Encoder -> Filter -> One Hot Encoder>
Label Encoder 다음으로 One Hot Encoder를 진행하였는데요.
그 전에 Filter를 통해 광역시도명은 상위 개로 구성,
자원인터넷 서비스의 경우 KT, LG , SK 그리고 DLIVE까지 들어간 통신사들로 구성하였습니다.

'광역시도명'의 경우 Count가 많은 순으로 하여,
서울특별시, 경기도, 부산광역시, 인천광역시, 경상남도, 대구광역시,
충청남도, 경상북도, 대전광역시, 충청북도, 전라남도, 전라북도 순으로
총 12개의 지역이 포함된 광역시도명만을 filter 하였습니다.

'자원인터넷서비스제공자'의 경우 또한 Count가 많은 순으로
Korea (KT), SK, LG, DLIVE가 포함된
총 4가지 이상의 통신사로 Filter 하였습니다.
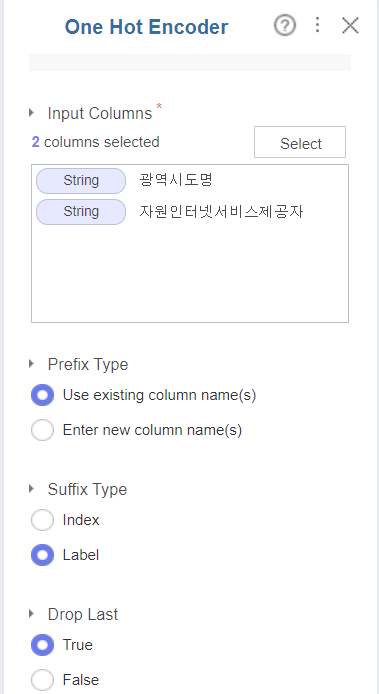
마지막으로 Suffix Type을 Label로 하였습니다.
예를 들어 '광역시도명_서울특별시'로 알아보기 쉽게 구성하였습니다.
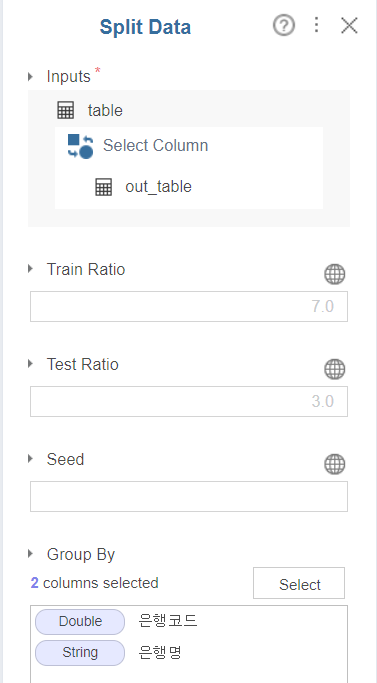
이 후 Split Data를 '은행명'을 group by하여 나눠주었고 모델링을 진행하였습니다.

<전반적인 모델링 프로세스>
모델링은 총 4가지의 모델로,
XGB Classification , AdaBoost Classification ,
Decision Tree Classification, Random Forest Classification
을 사용했습니다.
분류 모델
분류는 지도학습의 일종으로,
기존에 존재하는 데이터의 범주형 변수가 어떤 곳에 속할지를 예측하는 것입니다.
1. XGB Classification

xgboost의 분류모델의 경우,
day > month > age_index > sex_index 순으로 피처의 중요성이 나왔습니다.
이에 따른 accuracy는 0.22가 나왔습니다.
2. Adaboost Classification
adaboost의 분류모델의 경우,
month > 광역시도명_전라북도 > day > age_index 순으로 피처의 중요성이 나왔습니다.
이에 따른 accuracy는 0.20이 나왔습니다.
이 후 여러 분류 모델을 시행했으나. 비슷한 accuracy가 나왔습니다..!
사실상 데이터셋을 정하고, 분류 모델링을 진행하는데 있어
'은행명'을 Y변수로 지정한 것에 대해 뚜렷한 목적이 논리적으로 보이지 않았습니다.
뿐만 아니라 부족한 컬럼들로 인해 정확도가 낮은 것은 물론이고,
ML모델을 활용한 모델링의 구축이 쉽지 않았습니다..
'데이터 분석'에는 회귀나 분류와 같은 모델링 파트도 중요하지만,
데이터에 대한 자세한 탐색적 분석도 중요하다고 생각합니다.
모델링을 진행하는데 있어 부족한 데이터셋으로 생각하여
다음주에 '금융사기에 대한 데이터 분석'에 있어
결론지을 수 있을 내용들로 구성하여 돌아오겠습니다 :)
괜찮아. 딛고 일어서!
제게 해주는 말임니다 😅😅
프로젝트가 정확도가 높게 나오고,
성공적인 평가 지표로 이루어지라는 법은 없습니다.
'대부분의 프로젝트는 실패한다'는 말이 있듯
저 또한 모델링에 있어서는 실패했지만,
이와 다른 탐색적 분석에 대한 프로젝트는 실패하지 않았다고 생각합니다.
그렇기에 이번 프로젝트를 진행하면서 느꼈던 가장 중요한 점을 적어보려고 합니다.
- 분석에 대한 목표를 명확히 하자!
이번 프로젝트를 진행하면서 멘토님께서 몇차례 말씀해주셨습니다.
사실상 분석에 대한 목표가 희미해진다면, 분석에 대한 활용도 떨어질 뿐더러 좋은 분석의 결과물을 당연히 낼 수 없습니다.
2. 꼭 성공하라는 법은 없다.
모델링에 있어 정확도, f1 등의 수치가 계속 낮게 나와 여러 방법을 시도해봤습니다.
하지만 모델 프로세스에 대한 문제는 없고 데이터 셋의 구축에 있어 정보들이 부족함을 많이 느꼈습니다.
제가 위 포스팅 내용을 수정하지 않는 이유는
전환하는 그 과정을 고스란히 담는다면
저와 비슷한 상황에 있던 사람들도 같이 으쌰으쌰 하기를 바라는 마음에 남겨두었습니다.
아직 개인 분석 프로젝트에 대한 기간이 남아있기에
마지막까지 열심히 해보려고 합니다.
그럼 다음주에 알찬 내용으로 돌아오겠습니다 ㅎ_ㅎ



