
안녕하세요~!
브라이틱스 서포터즈 3기 서영석입니다 :)
저번 주 개인 분석 프로젝트를 시작으로
이어서 두번째 포스팅을 들고 왔습니다 😀😀
사실.. 저는 지금 한국에 없는데요!
tmi이긴 하지만.. 가족들과 유럽여행 중 카페에서 포스팅을 하고 있답니다 ㅋㅋ
약 한달간의 여행이기에 개인 분석 프로젝트를
유럽에서 모두 마무리 하려고 합니다 ㅎㅎ
이정도의 열정.. 보이시나요?
현재는 비행기 안이에요!
근데 브라이틱스 서버 연결이 WIFI를 통해 되는줄 알았는데,
비행기 안에서 연결이 되니 신기하네요~!!
- 비행기에서 브라이틱스하는 나.. 브스사랑이다 💙
다행히 브라이틱스의 서버는 이곳에서도 잘 열린답니다 헤헤
이번 주차는 ‘데이터간 연결’부터 연관성을 확인하는 작업까지!
‘데이터 MERGE 및 연관성, 상관성 파악’을 하려고 합니다 😊
데이터는
피해자의 연령 / 피해자의 나이 / 피해자의 통신사
금융사기에 이용된 증권 / 데이터에 이용된 1금융권
으로 총 5가지의 데이터를 사용하였습니다 .😊
0. 전반적인 프로세스
이제 데이터 병합과 각 변수들의 특성 파악 전에,
2-3주차에 걸쳐 진행될 전체적인 프로세스를 보여드리겠습니다.
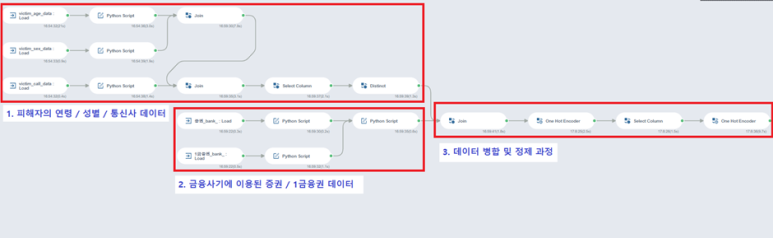
2주차에는 ‘피해자의 연령 / 성별 / 통신사 데이터’와
‘금융사기에 이용된 증권 / 1금융권 데이터’를
3주차에는 ‘데이터 병합 및 정제 과정’의
전반적인 내용을 다루도록 하겠습니다 😋
1. 범죄사기 피해자의 연령 / 성별 / 통신사 데이터
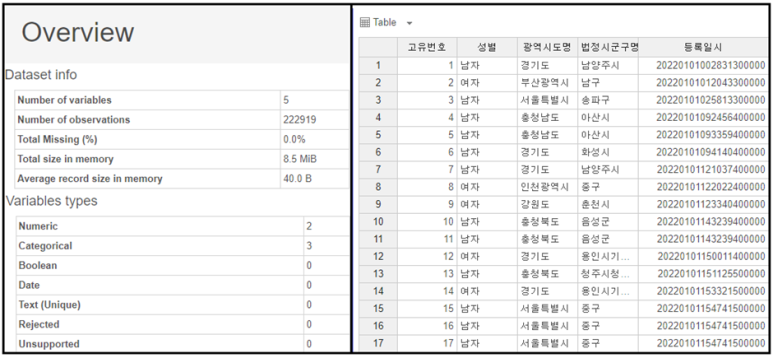
먼저 각 데이터의 정보를 먼저 보여드리겠습니다.
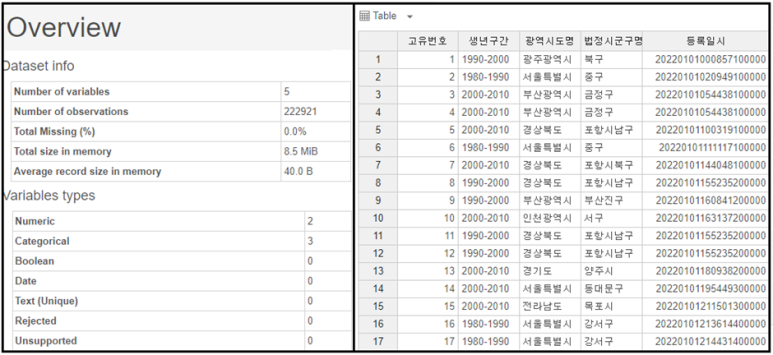
보시면 컬럼 수가 총 6개로 약 23만개의 데이터가 존재하네요!
생년구간으로 연령대를 유추할 수 있으며
지역명을 통해 피해자가
어느 도시에서 거주하는지를 알 수 있습니다 😊
<피해자의 연령 데이터>
컬럼 수가 5가지로 위와 동일하게
약 23만개에 가깝다는 것을 볼 수 있습니다.
‘피해자의 연령 데이터’와 마찬가지로
광역시도명, 법정시군구명, 등록일시는 같으며
성별이 남자 혹은 여자로 표시됨을 알 수 있습니다.
<피해자의 성별 데이터>
컬럼수는 3개, 통신사의 데이터는
약 17만개로 위 두 데이터보다 약간 적음을 알 수 있습니다.

<피해자의 통신사 데이터>
혹시 이 데이터들의 공통적인 부분이 보이시나요?
데이터를 병합하는데 있어서
중요한 점은 바로 병합할 수 있는 ‘KEY’ 인데요!
다행히 각 데이터의 ‘등록일시’가 하나의 KEY라고 볼 수 있습니다.
2. python script_데이터 병합을 위한 key

하지만 KEY를 ‘등록일시’로 해서
합치기에는 문제점이 하나 발생했는데요,

혹시 문제점을 발견하셨나요?
아차차... 같은 사람이어도 여러번 금융사기에 걸렸거나,
여러번 처리되는 경우 row가 추가됨을 볼 수 있습니다.
자세히 봐보실까요~!?
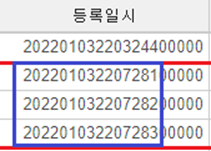
이처럼 같은 사람의 데이터여도
등록일시에서 마지막 숫자가 달라지는 경우가 발생했습니다.

물론, 다른 사람일 가능성도 배제할 수는 없었지만,
다른 데이터와 병합을 하였을 때,
결국 등록일시가 한쪽에서는 연속적이어도
다른 데이터에서는 같은 사람을 지칭하는 것을 볼 수 있었습니다.
이처럼 등록일시를
데이터 병합을 위한 KEY로 사용하기 위해
마지막 숫자를 제거해주며
데이터에 대한 정보를 자세히 보기 위해
Month(월)과 Day(일)을 추출해줍니다.
이와 관련된 python script의 코드입니다.
import pandas as pd
import numpy as np
import math
df = inputs[0]
df['datetime']= df['등록일시'].astype(str)
df['datetime_'] = pd.to_numeric(df['datetime'])
df['datetime_'] = df['datetime_'] //1000000
df['month'] = df['datetime'].str[5:7]
df['day'] = df['datetime'].str[7:9]
df = df.drop(columns=['datetime'])이렇게 만들어준 key는 ‘datetime_’ 입니다!
3. Join & Distinct
3.1 Join
데이터의 병합을 위해 key를 설정하는 작업을 진행하였으니,
병합을 위해 join을 해줍니다.
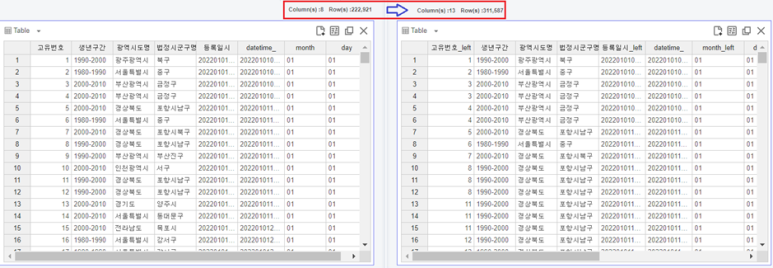
엥? 데이터의 수가 222,921개에서 311,587개로 훌쩍 늘었네요…?
이는 아까의 문제점이 현재에도 반영된 모습인데요.
이를 완벽하게 해결하기 위해 distinct 함수를 사용하여,
중복되는 데이터를 제거해주는 작업을 진행합니다.
3.2. Distinct
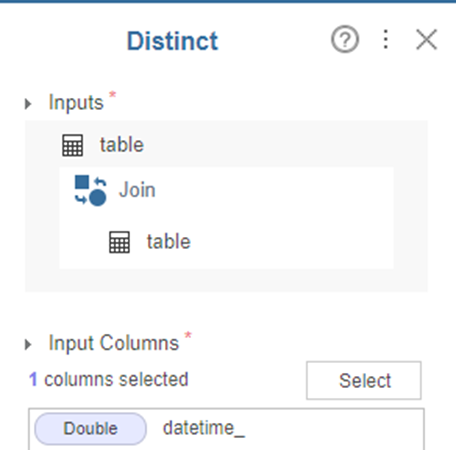
Input Columns에 datetime_을 넣으면 끝!
이로써 연령과 성별에 대한 데이터를 병합하여
총 175,518개의 데이터로 이루어집니다.
이제 통신사에 대한 데이터의 병합만 남았는데요,
같은 방법으로 이와 같이
Join -> Distinct의 과정만 거치면 완성됩니다!
금융과 관련된 데이터는 다음 포스팅에! 가져오도록 할게요 헤헤
4. 마무리
금융과 관련된 데이터를 제외한
데이터는 131,328개입니다.
또한 고유번호, 등록일시, datetime_, month, day,
성별, 생년구간, 광역시도명,
법정시군구명, 자원인터넷서비스로
총 10가지의 columns으로 이루어졌습니다.
이렇게 데이터를 뜯어보며 확인하는 시간을 거쳤는데요.
다음주에는
금융 데이터와의 병합
그리고 one hot encoding을 통한 데이터 정제,
전반적인 변수의 EDA 등
모델링 전까지의 작업을 수행해보려고 합니다.
다음주에는.. 아마 벨기에 카페에서 작업하지 않을까 싶어요 😊
그러면 다음주에 다시 돌아오겠습니다~!!

본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.



