
안녕하세요!
브라이틱스 서포터즈 3기 서영석입니다!
이번에는 팀 프로젝트의 세번째 진행에 대한 포스팅을 가져왔습니다!
이번 포스팅의 경우, 모델의 구성과 평가지표 위주로 하여 최적의 모델 선정까지 진행하였습니다.
이전 포스팅을 못보신 분들을
아래 링크로 한번 읽고 오시면.. 복받으실거에요😁
1️⃣ 개인이 납부할 의료비 예측 (1)
2️⃣ 개인이 납부할 의료비 예측 (2)
본격적으로 시작하기 앞서 전체적인 플로우를 약간 수정하였습니다.
이전 포스팅에서 저는
'로그변환' 부분을 맡아 프로젝트를 진행했는데요.
'로그변환은 선형회귀 알고리즘 적용시 유용하나,
tree 계열 알고리즘에서는 예측결과에 전혀 영향을 주지 않는다'
저희 멘토님께서 모델링에 앞서 좋은 조언을 해주셔서 변경하게 되었습니다.
그리하여 Linear의 경우 로그변환을, tree 계열의 경우 그대로 진행하기로 하였습니다.
00. 팀 분석 프로젝트 역할
이번 주 저의 역할은 모델을 구성하고 각 모델마다의 파라미터 최적화를 담당하였습니다.
이에 따라 저는 Filter를 통한 남/여 구분, linear, Randomforest, Adaboost regression에 대한 소개와
GridSearchCV를 통한 파라미터 최적화 그리고 모델링을 통한 평가지표 도출을 하였습니다.
linear regression의 경우 로그 변환 이 후의 모델링,
RandomForest 와 AdaBoost의 경우 로그 변환을 하지 않고 모델링을 진행한 뒤,
각 결과를 최종적으로 비교하여 최적의 모델을 선정하기로 하였습니다.
01. 가설
저희는 모든 변수를 담은 모델 구성 뿐만 아니라 개인에게 적합한 모델을 선정하는데 있어
세분화시키면 구체적인 모델을 세울 수 있을것이라고 생각했습니다. 그리하여
'성별에 따라 의료비를 예측하는데 있어 모델이 달라지지 않을까?'라는 가설을 세웠고
성별에 따라 모델의 구성과 평가지표가 어떻게 달라지는지에 대해 알아보려고 합니다.
그리하여 저는 linear regression과 RandomForest Regression, AdaBoost Regression에 대해
남자와 여자의 모델을 달리하여 모델링을 진행하였습니다.

02. 모델 구성

02-1. Linear Regression
linear regression은 선형 회귀로,
종속 변수 y와 한 개 이상의 독립 변수 X와의 선형 상관 관계를 모델링하는 회귀분석 기법입니다.

Split Data -> Linear Regression Train -> Linear Regression Test -> Evaluate Regression
02-2. RandomForest Regression
다음으로는 랜덤 포레스트 회귀 (RandomForest regression)입니다!
앙상블 학습 방법의 일종으로,
훈련 과정에서 구성한 다수의 결정 트리로부터 회귀 분석을 출력함으로써 동작합니다.
이전에 포스팅했던 글인데요. 참고하시길 바랍니다 😀
XGBoost vs Randomforest
데이터 사이언티스트(DS)로 성장하기 위해 모델의 분류와 모델에 관해 심도 깊은 이해가 필요하다. 그래...
blog.naver.com

Split Data -> RandomForest Regression Train -> RandomForest Regression Test -> Evaluate Regression
Python Script :RandomForest -> Evaluate Regression
02-3. Adaboost Regression
다음으로는 에이다부스트 회귀 (Adaboost regression)입니다!
Adaptive Boost의 줄임말로 약한 학습기(weak learner)의 오류 데이터에 가중치를 두어 더하는 알고리즘입니다.
초기에 포스팅했던 글인데요. 참고하시길 바랍니다 😀
부스팅 알고리즘
부스팅 알고리즘 종류 AdaBoost GBM(Gradient Boosting Machine) XGBoost LightGBM CatBoost AdaBoost Adaptive Boost의 줄임말로 약한 학습기(weak learner)의 오류 데이터에 가중치를 두어 더하는 알고리즘이다...
honeyofdata.tistory.com
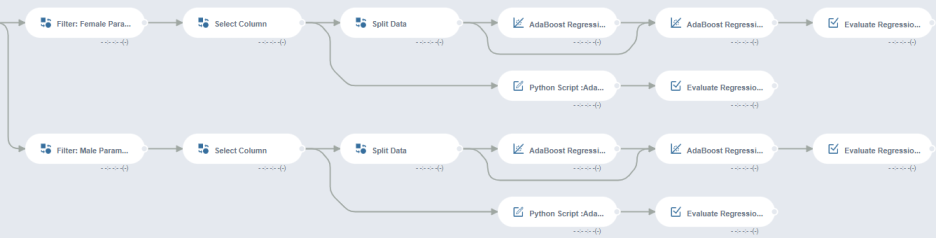
Split Data -> AdaBoost Regression Train -> AdaBoost Regression Test -> Evaluate Regression
Python Script :AdaBoost -> Evaluate Regression
02-4. 파라미터 최적화 - GridSearchCV 사용
Split Data로 데이터를 나누게 되면,
데이터의 불균형으로 인해 편향적인 모델 구성이 될 수 있습니다.
그렇기에 python script로 파라미터 최적화(gridsearchCV)와 교차 검증 (Cross Validation)를 진행하였고,
그에 대한 평가지표를 Evaluate Regression 함수를 통해 도출했습니다.
아래는 python script로 작성한 코드입니다.
data = inputs[0]
X_train, X_test, y_train, y_test = train_test_split(
data.iloc[:,:-1], data.iloc[:,-1], test_size=0.3, random_state=0)
parameters = {
"n_estimators": [10,12,13,14,15, 16, 17, 18],
"max_depth": [2,4,5,7],
"min_samples_leaf": [1,3,5,7,9,11],
"min_samples_split": [3,5,7,9,11,13],
"max_features" : ['sqrt', 'log2', None] }
clf = RandomForestRegressor()
rf_model = GridSearchCV(clf, param_grid = parameters,cv =5)
rf_model.fit(X_train, y_train)
best_params = rf_model.best_params_
best_model = rf_model.best_estimator_
y_predict = rf_model.predict(X_test)
df = pd.DataFrame({'charges': y_test ,'prediction': y_predict})- RandomForest python script-
data = inputs[0]
X_train, X_test, y_train, y_test = train_test_split(
data.iloc[:,:-1], data.iloc[:,-1], test_size=0.3, random_state=0)
ada=AdaBoostRegressor()
parameters = {
'n_estimators':[30,40,50,80,100],
'learning_rate':[0.0001,0.001,0.01,0.05],
'loss':['linear','square','exponential']}
ada_grid = GridSearchCV(ada,parameters,cv = 5)
ada_grid.fit(X_train,y_train)
best_model =ada_grid.best_estimator_
y_predict = ada_grid.predict(X_test)
df = pd.DataFrame({'charges': y_test ,'prediction': y_predict})
-AdaBoost python script-
이렇게 각 모델에 대한 설명과 gridsearchCV에 대한 정리를 하였습니다 :)
03. Filter (남 / 여 구분)
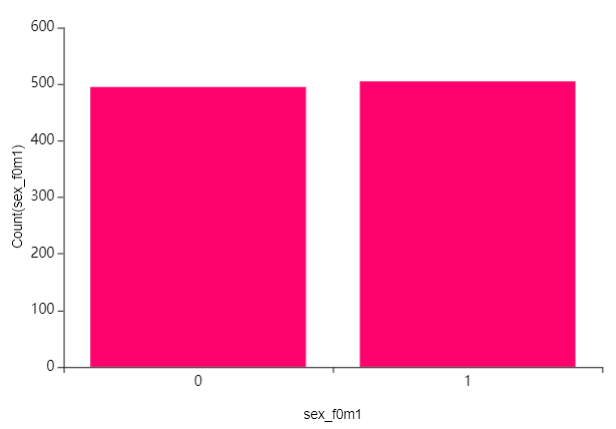
앞서 설명했듯이 모델링의 경우 남자와 여자로 나눠 진행을 했는데요,
보시다시피 성별이 비슷한 것으로 보아 편향적이지 않음을 알 수 있습니다.
이에 따라 남/여 구분에 대한 Flow는 다음과 같습니다.
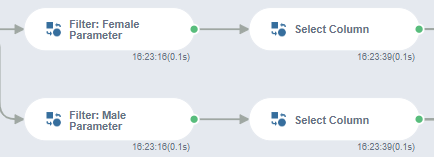
Filter(남/여 분류) -> Select Column(성별 제외)
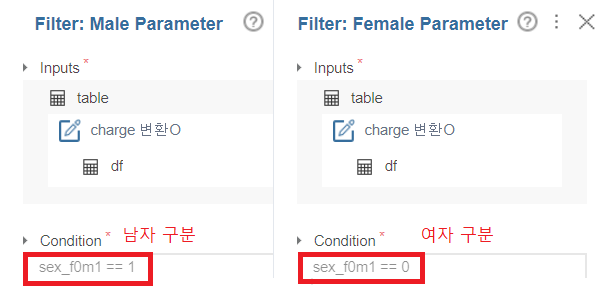
Filter를 통한 남/여 분류
이제 남자와 여자의 경우를 나누어 linear, RandomForest, Adaboost로 모델링을 진행해보겠습니다!
04. Male (남성)의 모델링
04-1. Linear Regression
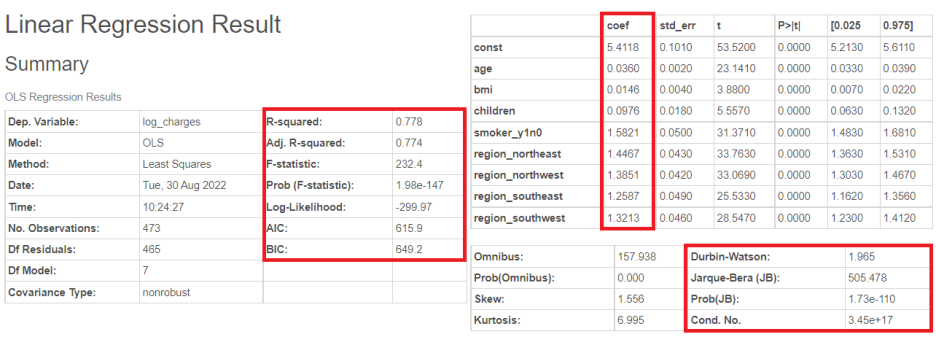
linear regression train을 돌리게 되면,
이렇게 다양한 정보를 한 눈에!!
저기 R-squared나 AIC 등도 보이고 아래 보시면 저번 포스팅에 다뤘던 쟈크베라 검정도 보이네요!
브라이틱스로 다양한 정보를 보여주니, 바로바로 모델의 구성을 파악할 수 있습니다.
(안 쓸래야.. 안쓸수가 ㅎㅎ역시 갓라이틱스.. )
이에 따라 브라이틱스에서 제공하는 시각화를 봐볼까요?
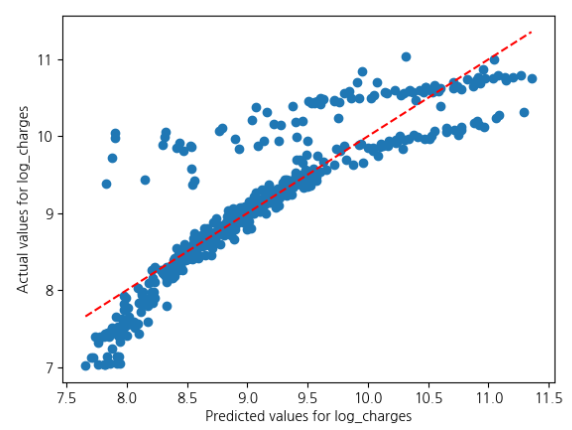
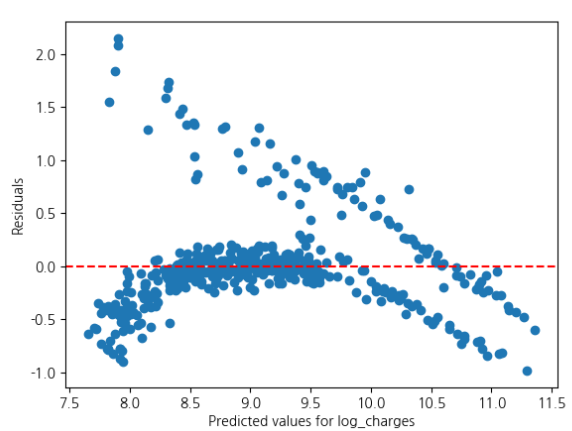

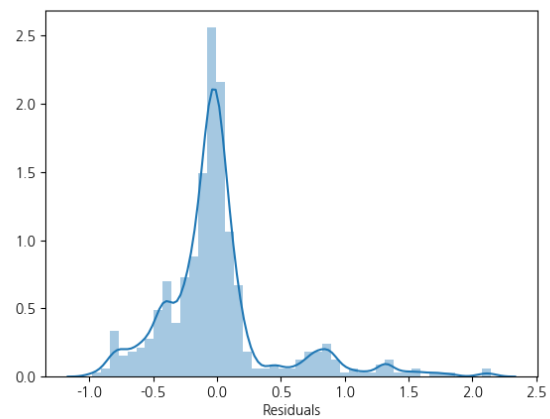
이처럼 예측값과 현재값의 관계, 잔차와의 관계를 한 눈에 볼 수 있습니다.
다음으로는 평가지표입니다.
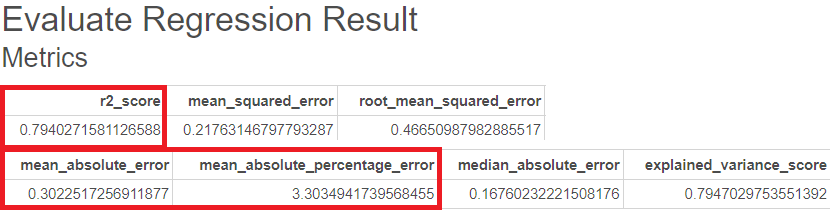
R-sqaure는 0.79, MAE는 0.3, MAPE는 3.3이 나온 것을 볼 수 있습니다.
04-2. RandomForest Regression
다음으로는 RandomForest Regression입니다.
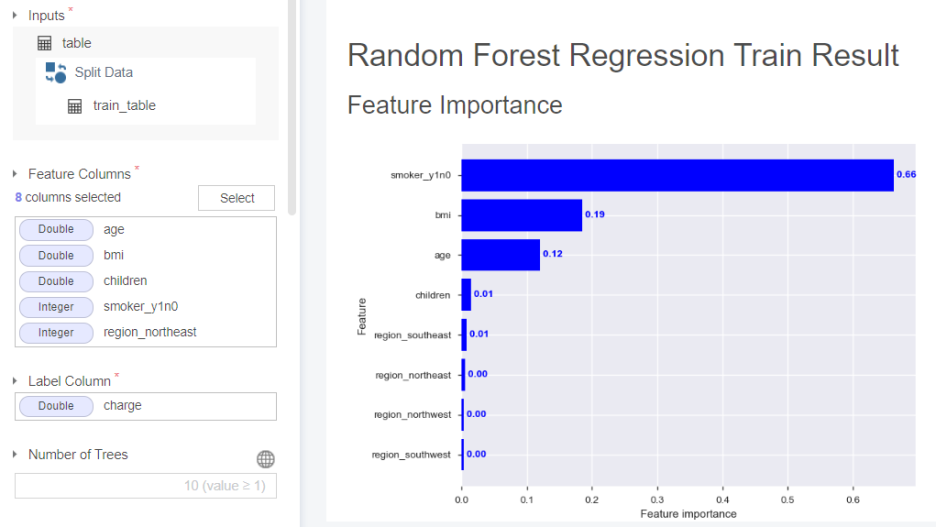
feature importance가 흡연 유무, 비만도, 나이 순으로 구성됨을 알 수 있습니다.
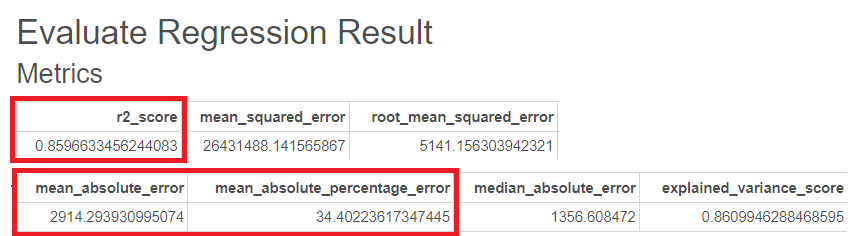
R-sqaure는 0.86, MAE는 2914, MAPE는 34이 나온 것을 볼 수 있습니다.
다음은 RandomForest의 GridSearchCV를 통한 평가지표입니다.
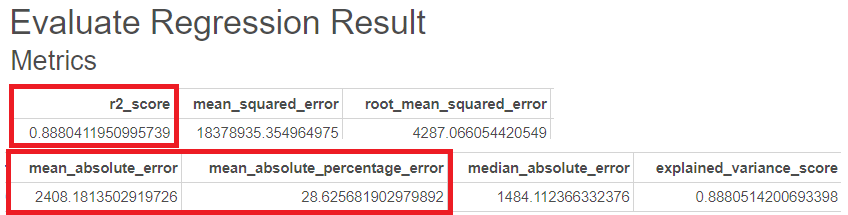
R-sqaure는 0.89, MAE는 2408, MAPE는 29로 더 나은 성능이 나온 것을 볼 수 있습니다.
04-3. AdaBoost Regression
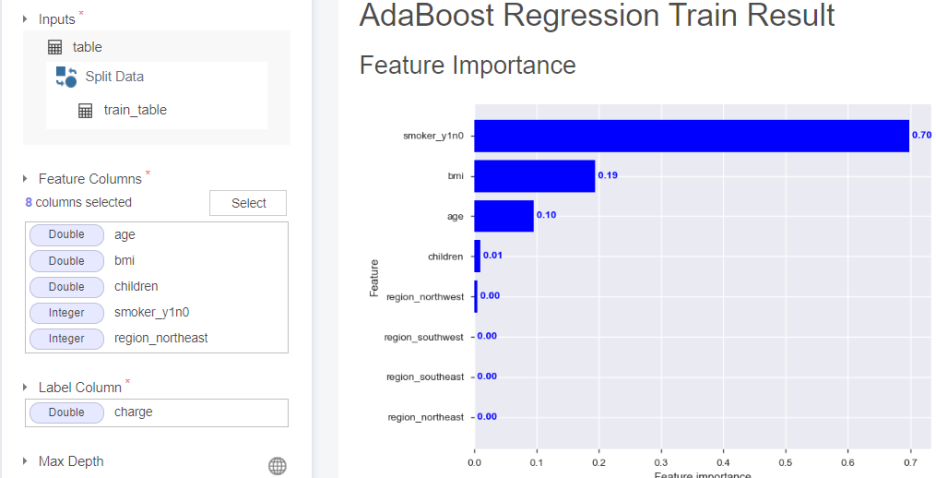
feature importance가 흡연 유무, 비만도, 나이 순으로 구성됨을 알 수 있습니다.

Adaboost의 경우 R-sqaure는 0.84, MAE는 4491, MAPE는 92이 나온 것을 볼 수 있습니다.
다음은 Adaboost의 GridSearchCV를 통한 평가지표입니다.
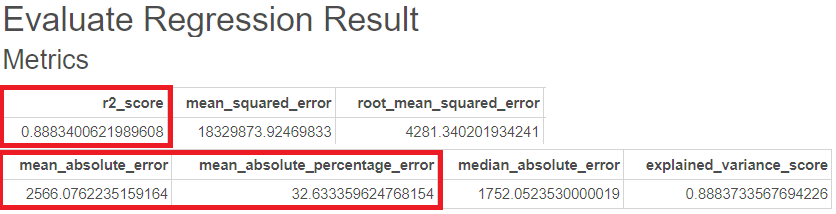
R-sqaure는 0.89, MAE는 2566, MAPE는 33로 train시킨 것이 더 괜찮은 것을 볼 수 있습니다.
05. Female (여성)의 모델링
05-1. Linear Regression
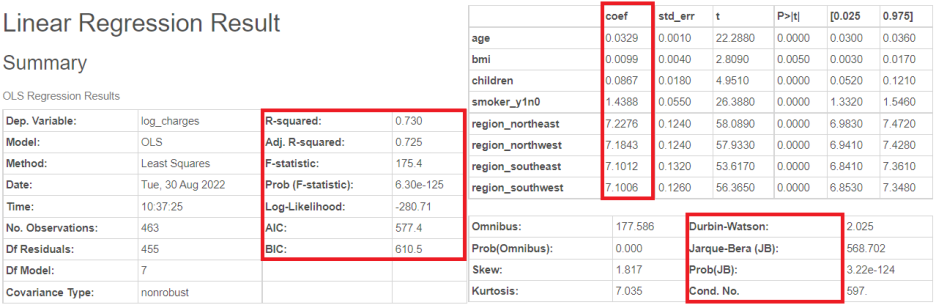
또 한번 보는 brightics의 다양한 정보들..!!!
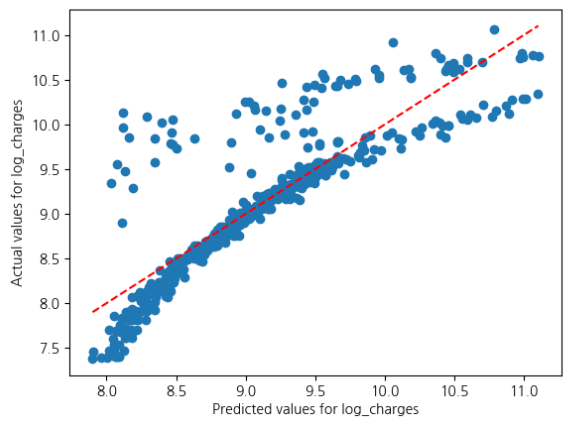

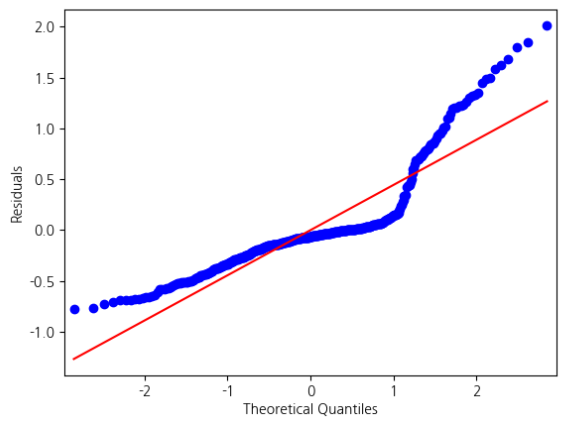
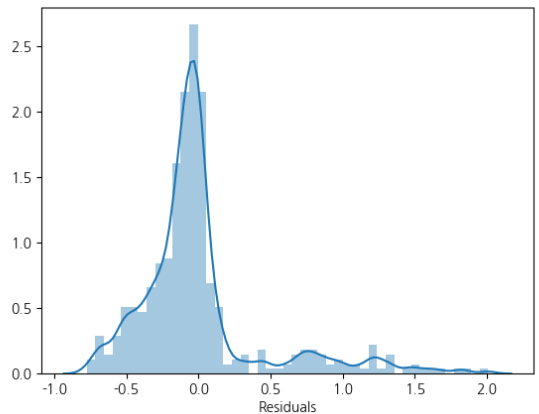
Fit Diagnostics
남자일 때의 그래프와 비교해보면 약간씩 다름을 알 수 있습니다.
그렇기에 linear regression 모델의 선정 혹은 성능도 달라질 수 있습니다.
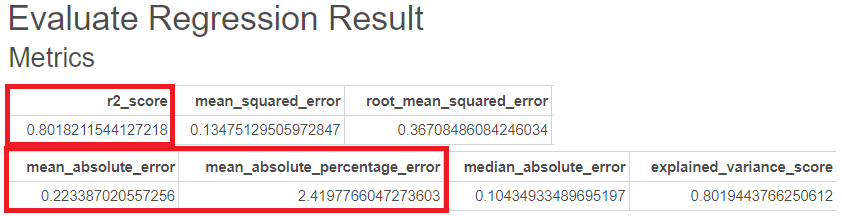
R-sqaure는 0.80, MAE는 0.22, MAPE는 2.42이 나온 것을 볼 수 있습니다.
05-1. RandomForest Regression
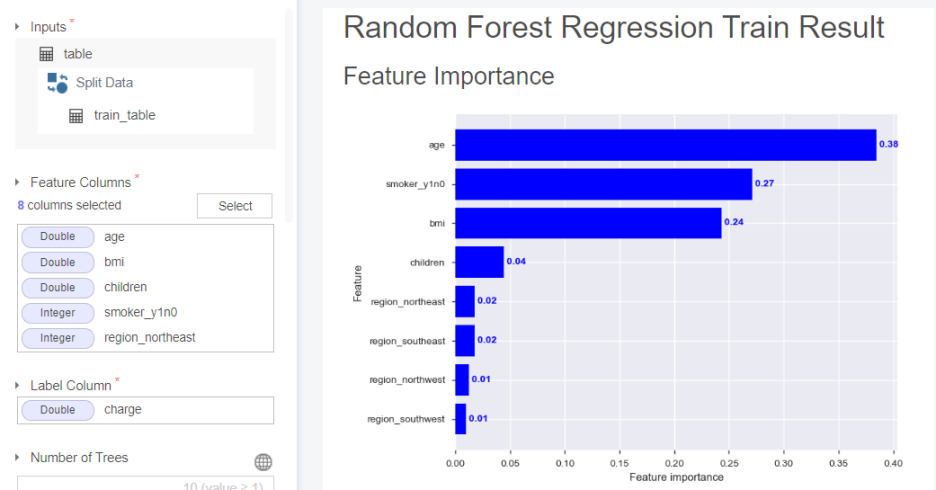
feature importance가 나이, 흡연 유무, 비만도 순으로 구성됨을 알 수 있습니다.
(남자의 경우와 피쳐 중요도가 약간씩 다르네요~!!)
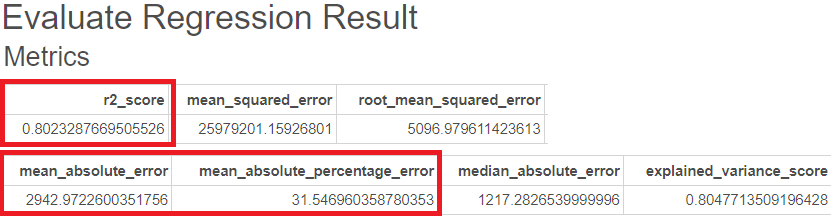
R-sqaure는 0.80, MAE는 2943, MAPE는 32이 나온 것을 볼 수 있습니다.
다음은 RandomForest의 GridSearchCV를 통한 평가지표입니다.
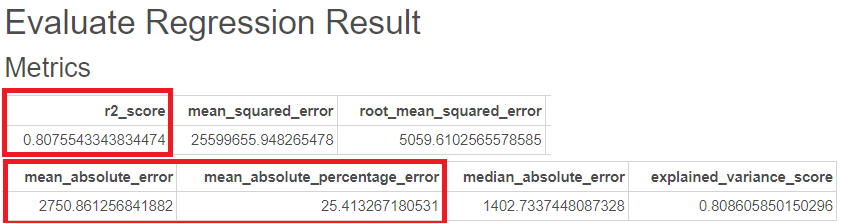
R-sqaure는 0.80, MAE는 2750, MAPE는 25로 더 나은 성능이 나온 것을 볼 수 있습니다.
05-3. AdaBoost Regression
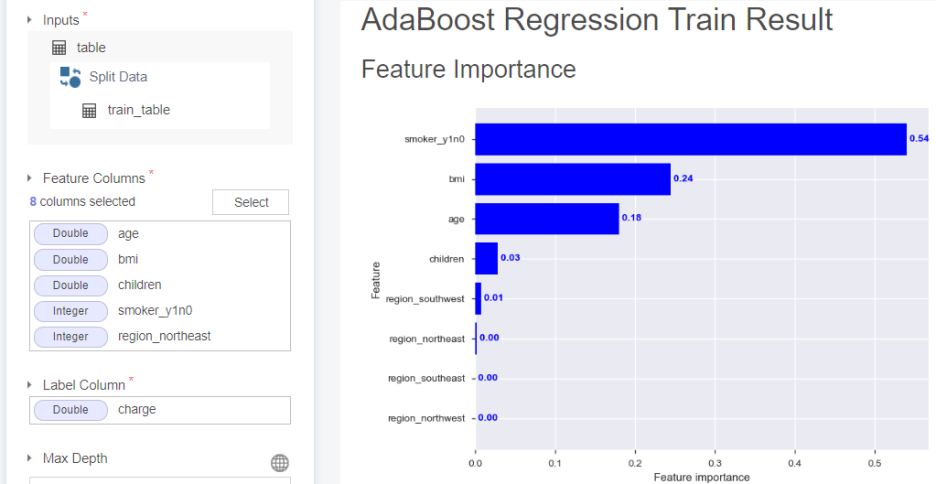
feature importance가 흡연 유무, 비만도, 나이 순으로 구성됨을 알 수 있습니다.
(이는 남자의 경우와 같습니다. 흡연이 영향을 많이 미치네요..)
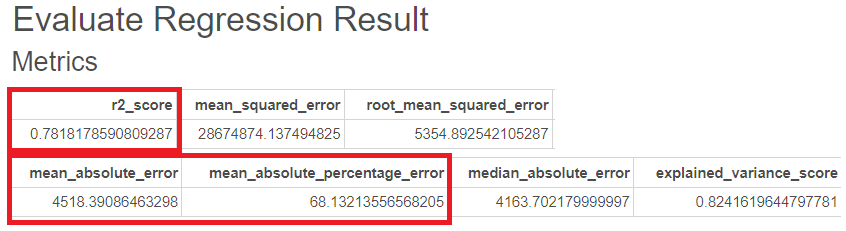
Adaboost의 경우 R-sqaure는 0.78, MAE는 4518, MAPE는 68이 나온 것을 볼 수 있습니다.
다음은 Adaboost의 GridSearchCV를 통한 평가지표입니다.
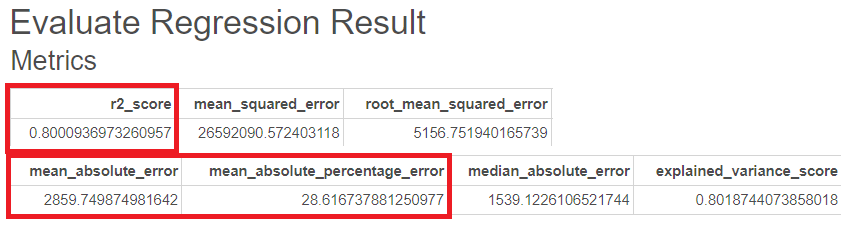
R-sqaure는 0.80, MAE는 2860, MAPE는 29로 더 나은 성능인 것을 볼 수 있습니다.
06. 모델 선정
|
남자 모델구성
|
구분
|
R-squared
|
MAE
|
MAPE
|
|
Linear Regression
|
-
|
0.794027
|
0.30225172
|
3.30349417
|
|
RandomForest Regression
|
일반적 Train
|
0.8596633
|
2914.29393
|
34.402236
|
|
GridSearchCV
|
0.8880412
|
2408.18135
|
28.625682
|
|
|
AdaBoost Regression
|
일반적 Train
|
0.8380054
|
4491.32780
|
91.662305
|
|
GridSearchCV
|
0.8883401
|
2566.07622
|
32.633360
|
남자의 경우, RandomForest를 GridSearchCV를 이용하여 모델을 돌린 것이 잘 나왔음을 알 수 있습니다.
|
여자 모델구성
|
구분
|
R-squared
|
MAE
|
MAPE
|
|
Linear Regression
|
-
|
0.8018212
|
0.2233870
|
2.4197766
|
|
RandomForest Regression
|
일반적 Train
|
0.8023288
|
2942.97226
|
31.546960
|
|
GridSearchCV
|
0.8075543
|
2750.86126
|
25.413267
|
|
|
AdaBoost Regression
|
일반적 Train
|
0.7818179
|
4518.39086
|
68.132136
|
|
GridSearchCV
|
0.8000937
|
2859.74987
|
28.616738
|
여자의 경우, RandomForest를 GridSearchCV를 이용하여 모델을 돌린 것이 잘 나왔음을 알 수 있습니다.
이에 따라 구성된 모델들 중 RandomForest가 가장 낫다고 결론지을 수 있게 되었습니다.
이와 관련되어 최종 모델 선정은 저희 팀원들의 블로그를 참고하시면 보실 수 있습니다 :)
07. 느낀점
저는 프로젝트를 한 주차씩 진행할 때마다 분석에 있어 많이 배워가는 것 같아요!
단위근 검정과 정규성 검정에 대해서도 자세히 다룰 수 있었고,
이번 주차에는 '로그변환의 쓰임'과 '로그변환을 사용할 시기'에 대해서도 자세히 알 수 있었습니다.
뿐만 아니라 각 모델마다의 쓰임과 특징들 그리고 자세히 GridSearchCV를 사용하며 최적화하는 과정까지 포스팅을 하려다보니, 정확한 정보를 올려야겠다는 사명감에 자세히 찾아보는 시간이 되었습니다 😉
또한 우리 팀원들이 바쁜 와중에도 열정적인 회의를 거쳐 열심히 하는 모습에
저 또한 책임감을 갖고 더 열심히 그리고 자세히 공부하며 프로젝트를 진행하고
피드백을 주고 받으려고 노력하고 있습니다.
어떻게 하면 잘 진행하고 완성하지? 라는 마음을 매일 품는 것 같아요.
브라이틱스를 매일 사용하다보니 계속 애착이 가고...
이러다 브라이틱스랑 사랑에 빠지는게 아닌지.. 걱정이 됩니다 💙
앞으로도 저의 포스팅 기대해주세요!
그러면 다음주에 찾아뵙겠습니다!!

본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다
'가치를 창출하는 데이터 분석 > Brightics AI 데이터 분석' 카테고리의 다른 글
| [삼성 SDS Brightics]# 04-1. 팀 영상 프로젝트(1) 유한상사로 취업하다!? (0) | 2022.09.15 |
|---|---|
| [삼성 SDS Brightics]# 03-4. 팀프로젝트(4) 의료비 예측 마무으리!! (0) | 2022.09.06 |
| [삼성 SDS Brightics]# 03-2. 팀프로젝트(2) 의료비(보험비) 예측 (0) | 2022.08.23 |
| [삼성 SDS Brightics]# 03-1. 팀프로젝트(1) 의료비(보험비) 예측 (0) | 2022.08.16 |
| [삼성 SDS Brightics]# 02-3. 개인프로젝트(3) Kaggle 평균 기온 예측하기 - 시계열 분석 (ARIMA / Hot-Winters) (0) | 2022.07.13 |



