A conversation with Andrew Ng, Robert Crowe and Laurence Moroney
Specialization overview
프로젝트 범위 지정에서 데이터, 모델링, 배포에 이르기까지 전체 머신러닝 프로젝트 수명 주기에 대해 배우게 된다.
이 모든 작업을 수행하기 위한 프로세스 및 도구를 MLOps 또는 머신러닝 작업이라고 부른다.
강사진
Andrew Ng : Coursera 창업자
Robert Crowe : Google, TensorFloew 개발자이자 Google 엔지니어
Laurence Moroney : Google에서 AI advocacy를 이끌고 딥러닝AI를 사용하는 Tensorflow 전문 분야의 강사
The Machine Learning Project Lifecycle
Welcome
머신러닝 모델을 구축할 뿐만 아니라 프로덕션에도 적용해야한다.
이에 따라 교육 모델에서 생산에 투입하고 실제로 머신러닝 프로젝트를 관리하는 방법을 알아야 한다.
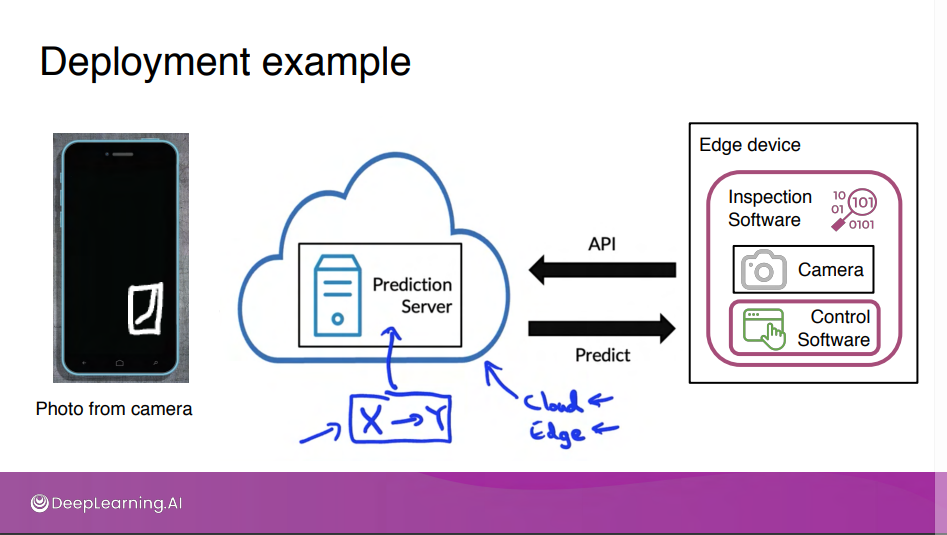
예를 들어 컴퓨터 비전을 사용하여 제조 라인에서 나오는 전화를 검사해 결함이 있는지 확인한다고 가정하자.
작은 스크래치가 있는 경우 CV 알고리즘은 이러한 유형의 스크레치를 찾을 수 있어야한다.
스크레치 난 폰의 데이터 셋을 얻은 경우 이러한 유형의 결함을 감지하기 위해 네트워크에서 CV알고리즘을 훈련시킬 수 있다.
Edge device : 스마트폰을 제조하는 공장 내부에 있는 장치
automated visual defect inspection : 스마트폰의 사진을 찍고, 스크레치가 있는지 확인 뒤 여부를 결정하는 검사 소프트웨어
학습 알고리즘을 train 한 뒤,신경망을 train하여 입력X로 사용.
전화기에 결함이 있는지 여부에 대한 y예측을 매핑.

Prediction Server에 넣고 API 인터페이스 설정한 뒤 소프트웨어를 작성.
Steps of an ML Project
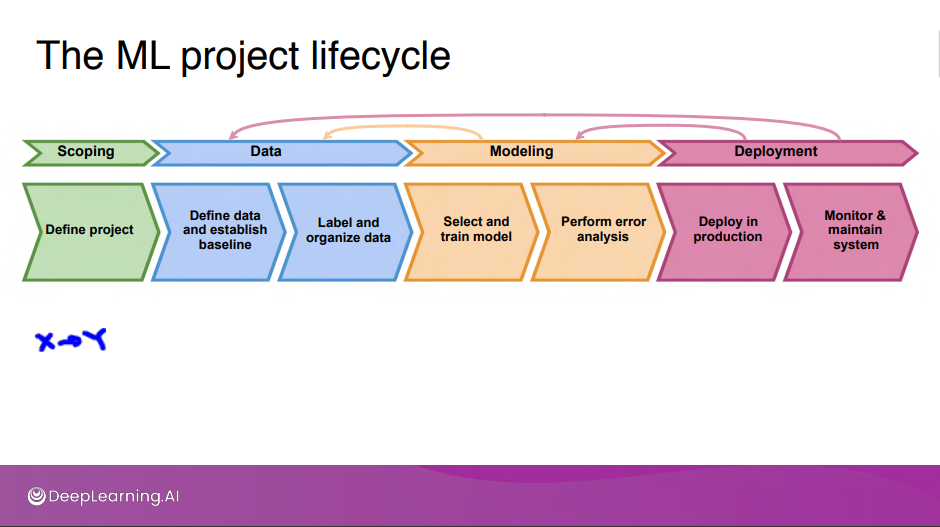
머신러닝 시스템을 구축할 때, 수명 주기를 통해 생각하는 것은 작업에 필요한 모든 단계를 계획하는데 효과적이다.
머신러닝 프로젝트의 주요 단계이다.
1. Scoping : 프로젝트를 정의하거나 작업할 항목을 결정해야 하는 범위 지정이다.
- 정확히 머신러닝을 적용하고 싶은것이 무엇인지, X와 Y 에 대한 선택과 데이터를 수집, 알고리즘에 필요한 데이터를 획득해야한다.
2. Data : 데이터를 정의하고 기준선을 설정한 다음 데이터에 레이블 지정 및 구성하는 작업이다.
3. Modeling : 모델을 훈련해야 하고 오류 분석도 수행해야 한다.
4. Deployment : 시스템을 배포하기 전 오류 분석의 일환으로 시스템의 성능이 충분하고 응용 프로그램에 대해 신뢰할 수 있는지에 대한 검사를 수행한다.
Case study: speech recognition
딥러닝의 성공 중 하나는 음성 인식이다.
음성 인식을 예로 들어 설명.

1. Scooping : 프로젝트를 정의하고 음성 인식 작업을 결정해야 한다.
예를 들어 프로젝트 정의의 일부로 음성 검색을 수행한다.
또한 핵심 지표를 추정하거나 최소한 추정하도록 권장한다.

2. Data : 데이터를 정의하고 기준선을 설정하고 데이터에 레이블을 지정하고 구성해야 하는 데이터 단계
실용적인 음성 인식 시스템의 과제 중 하나는 일관된 데이터 레이블이다.

3. Modeling : 모델을 선택하고 교육하고 오류 분석을 수행해야 하는 모델링이다.
세 가지 주요 입력은 알고리즘, 신경망 모델 아키텍처, 하이퍼파라미터 선택이다.

4. Deployment : 배포와 관련하여 주요 과제 중 하나는 개념 드리프트 또는 데이터 드리프트이다.
'공부하는 습관을 들이자' 카테고리의 다른 글
| LLM 평가·벤치마크 : PoC에서 무엇을 기준? (0) | 2025.09.14 |
|---|---|
| RAG 구조 설계기: RePlug와 ColBERTv2 (0) | 2025.09.02 |
| XGBoost vs Randomforest (0) | 2022.06.29 |
| [Dacon study] 2. 타이타닉 생존자 예측 (0) | 2022.02.19 |
| [Dacon study] 1. 영화 관객수 예측 모델 개발 (0) | 2022.02.14 |

