이때까지 파이썬과 분석 공부를 하였지만,
다시 데이터 분석과 머신러닝의 기초부터 차근차근 시작하자..는 생각으로 시작했다.
그리하여 데이콘에서 영화 관객수 예측 모델 개발부터 시작하였다.

https://dacon.io/competitions/open/235536/data
[문화] 영화 관객수 예측 모델 개발 - DACON
좋아요는 1분 내에 한 번만 클릭 할 수 있습니다.
dacon.io
영화 관객수를 예측하는 대회이며 누구나 참여할 수 있는 연습용으로 적절한 대회이다.
데이터 설명
movies_train.csv / movies_test.csv
- title : 영화의 제목
- distributor : 배급사
- genre : 장르
- release_time : 개봉일
- time : 상영시간(분)
- screening_rat : 상영등급
- director : 감독이름
- dir_prev_bfnum : 해당 감독이 이 영화를 만들기 전 제작에 참여한 영화에서의 평균 관객수(단 관객수가 알려지지 않은 영화 제외)
- dir_prev_num : 해당 감독이 이 영화를 만들기 전 제작에 참여한 영화의 개수(단 관객수가 알려지지 않은 영화 제외)
- num_staff : 스텝수
- num_actor : 주연배우수
- box_off_num : 관객수
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')# 한글 폰트로 나오는 코드
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
if platform.system() == 'Windows':
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
print('Windows version')train = pd.read_csv("./1. 영화 관객수/movies_train.csv")
test = pd.read_csv('./1. 영화 관객수/movies_test.csv')
submission = pd.read_csv('./1. 영화 관객수/submission.csv')train.columns
test.columns
이처럼 우리가 예측해야할 피쳐는 'box_off_num'임을 알 수 있다.
train.groupby('genre').box_off_num.mean().sort_values()장르별 영화 관객수를 평균값으로 랭크 인코딩을 하였다.

print(train.shape)
print(test.shape)
print(submission.shape)
shape를 확인해보니 train과 test의 비율이 약 5:2정도로 나뉨을 볼 수 있다.
산포도 비교
스탭수와 관객수의 산포도
plt.figure(figsize=[10,10])
sns.scatterplot(data=train, x='num_staff', y = 'box_off_num')
상영시간(분)과 관객수의 산포도
plt.figure(figsize=[10,10])
sns.scatterplot(data=train, x='time', y = 'box_off_num')
장르와 관객수의 산포도
plt.figure(figsize=[10,5])
sns.scatterplot(data=train, x='genre', y = 'box_off_num')
주연배우수와 관객수의 산포도
plt.figure(figsize=[10,10])
sns.scatterplot(data=train, x='num_actor', y = 'box_off_num')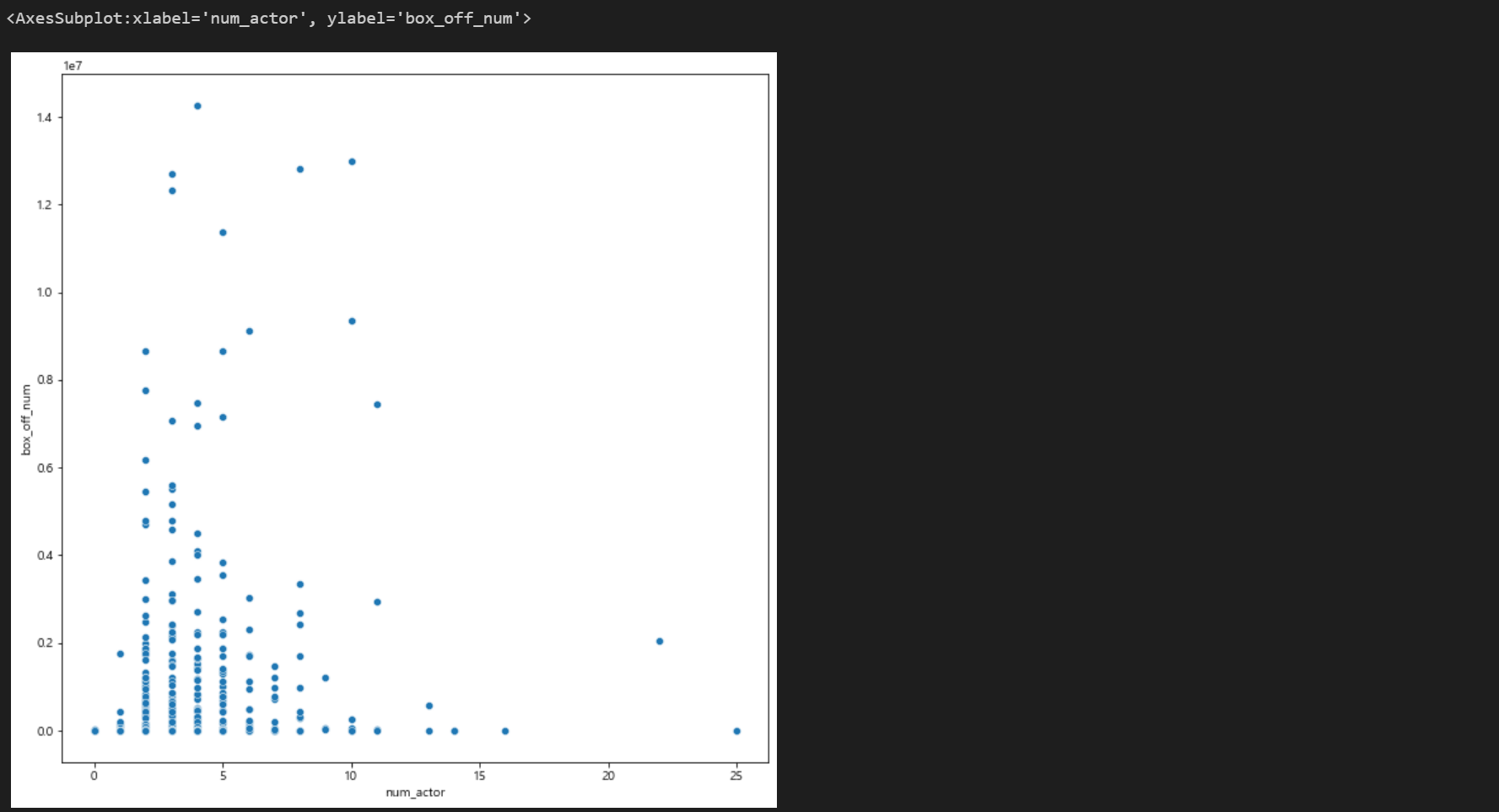
여기서 주연배우수와 관객수의 산포도가 핵심이다.
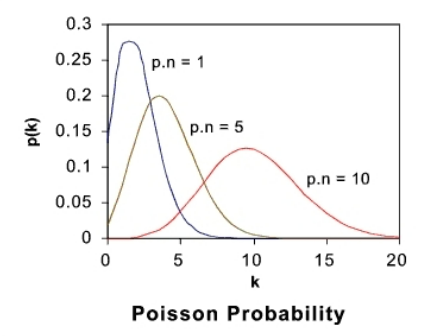
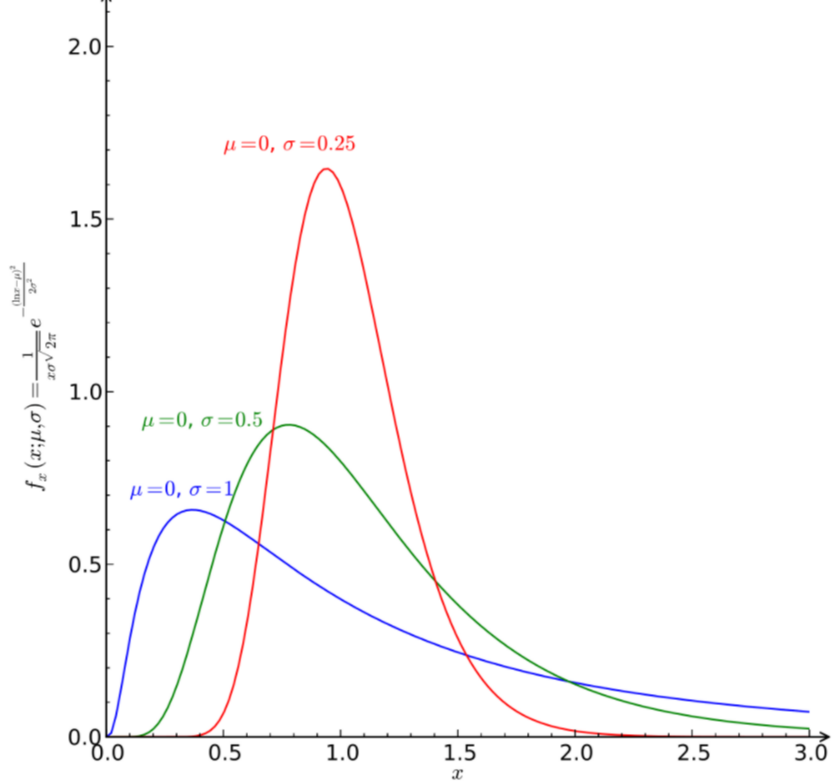
이 산포도는 포아송을 따르는 양상도 보이며, 로그함수를 따르는 양상도 보인다.
상관계수 히스토그램
sns.heatmap(train.corr(), annot = True)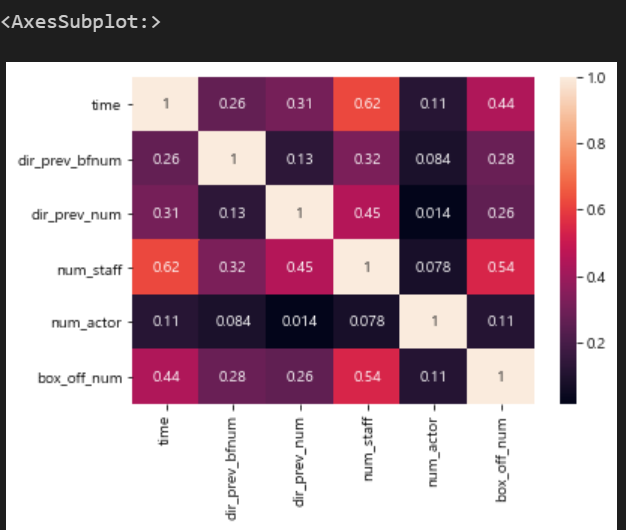
결측치 처리
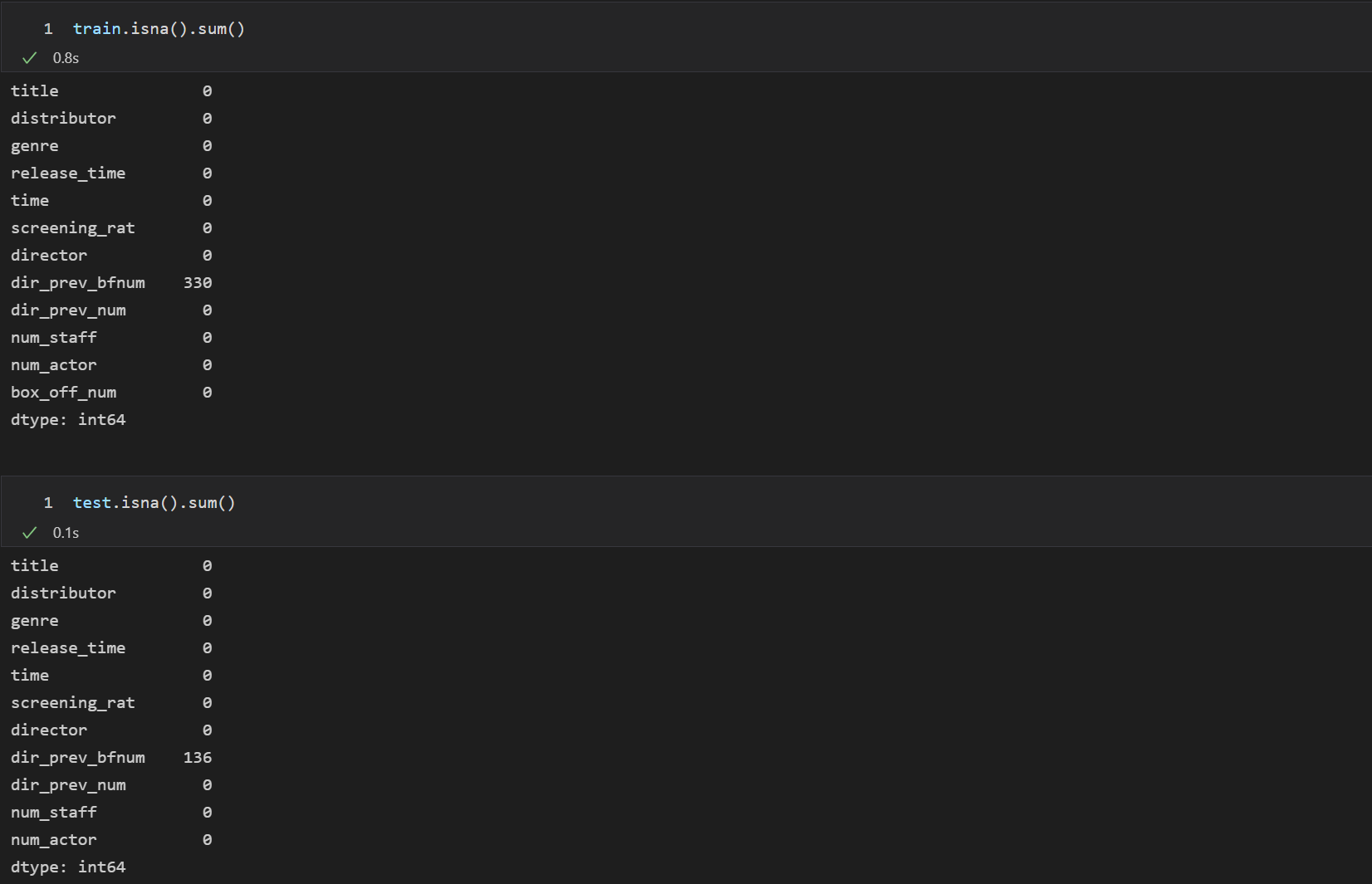
dir_prev_bfnum에 각각 330, 136의 결측치가 있음을 볼 수 있다.
dir_prev_num에서 0일 때 dir_prev_bfnum이 NaN임을 알 수 있다.
다시 말해서 해당 감독이 처음 영화를 만들었을 때, 당연히 dir_prev_bfnum인 해당 감동이 전 제작에 참여한 영화에서의 평균 관객수가 NaN이므로 이는 0일 수 밖에 없다.
그러므로 모든 결측치를 0으로 대체해주면 된다.
train['dir_prev_bfnum'].fillna(0,inplace=True)
test['dir_prev_bfnum'].fillna(0,inplace=True)장르 전처리 (숫자로 구분)
train['genre_rank'] = train.genre.map({'뮤지컬' : 1, '다큐멘터리' : 2, '서스펜스' : 3, '애니메이션' : 4, '멜로/로맨스' : 5,
'미스터리' : 6, '공포' : 7, '드라마' : 8, '코미디' : 9, 'SF' : 10, '액션' : 11, '느와르' : 12})
test['genre_rank'] = test.genre.map({'뮤지컬' : 1, '다큐멘터리' : 2, '서스펜스' : 3, '애니메이션' : 4, '멜로/로맨스' : 5,
'미스터리' : 6, '공포' : 7, '드라마' : 8, '코미디' : 9, 'SF' : 10, '액션' : 11, '느와르' : 12})배급사 랭크 인코딩
nm_rank = train.groupby('distributor').box_off_num.median().reset_index(name = 'num_rank').sort_values(by = 'num_rank')
nm_rank['num_rank'] = [i + 1 for i in range(nm_rank.shape[0])]
nm_rank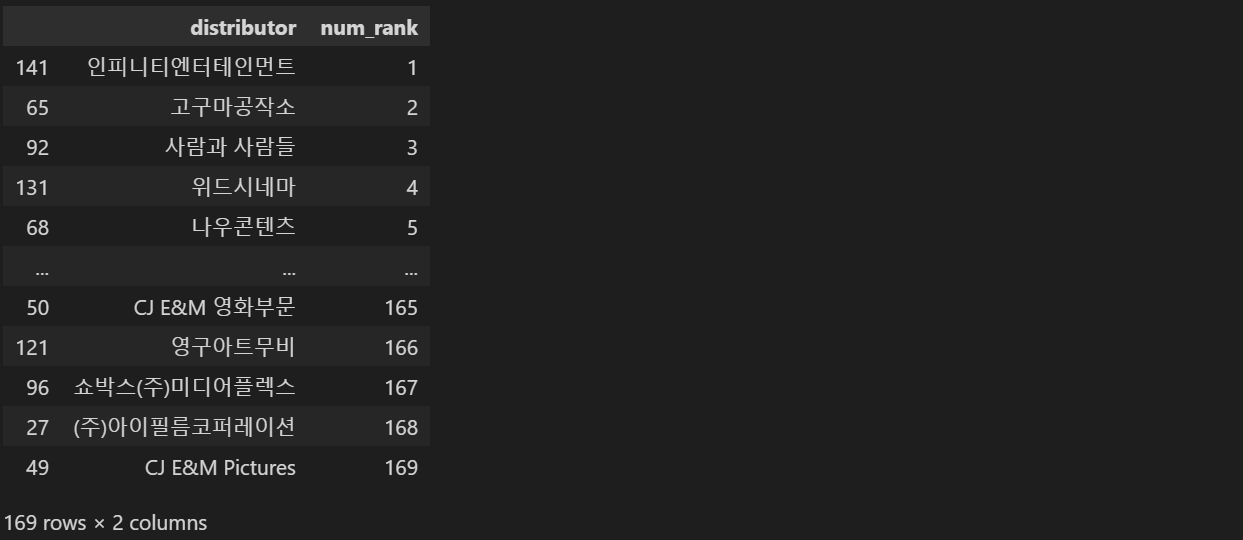
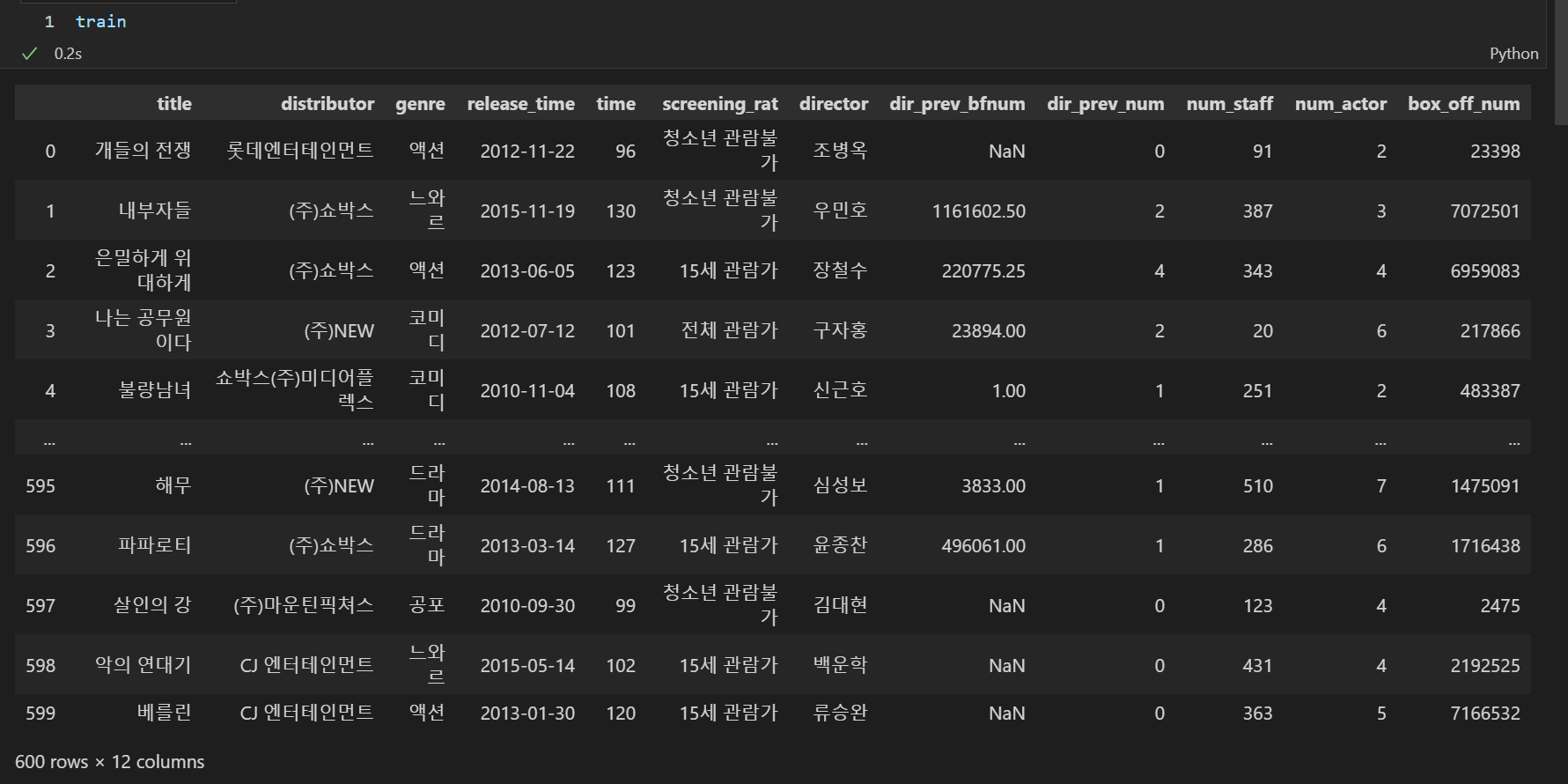
최종 데이터 병합
train = pd.merge(train, nm_rank, how = 'left')
test = pd.merge(test, nm_rank, how = 'left')test.fillna(0, inplace = True)모델링 사용
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import KFold관객수 : 로그변환
출연 배우 수 : 로그변환 (산점도 참고)
상영등급 : 더미변수
1. 관객수 로그변환.
X = train[['num_rank', 'time', 'num_staff', 'num_actor', 'genre_rank', 'screening_rat']]
y = np.log1p(train.box_off_num)2. 상영등급 더미변수 변환.
X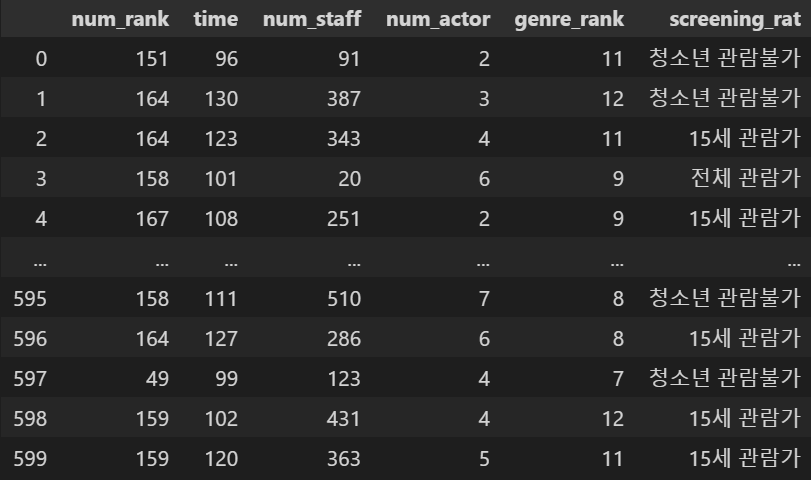
X = pd.get_dummies(columns = ['screening_rat'], data = X)
X
3. 출연 배우수 로그변환
X['num_actor'] = np.log1p(X['num_actor'])test데이터 또한 1,2,3의 과정을 거친다.
target = test[['num_rank', 'time', 'num_staff', 'num_actor', 'genre_rank', 'screening_rat']]
target = pd.get_dummies(columns = ['screening_rat'], data = target)
target['num_actor'] = np.log1p(target['num_actor'])K-Fold (10겹 검증)
kf = KFold(n_splits = 10, shuffle = True, random_state = 42)모델 사용
1 . GradientBoostingRegressor
gbm = GradientBoostingRegressor(random_state = 42)
rmse_list = []
gb_pred = np.zeros((test.shape[0]))
for tr_idx, val_idx in kf.split(X, y) :
tr_x, tr_y = X.iloc[tr_idx], y.iloc[tr_idx]
val_x, val_y = X.iloc[val_idx], y.iloc[val_idx]
gbm.fit(tr_x, tr_y)
pred = np.expm1([0 if x < 0 else x for x in gbm.predict(val_x)])
sub_pred = np.expm1([0 if x < 0 else x for x in gbm.predict(target)])
rmse = np.sqrt(mean_squared_error(val_y, pred))
rmse_list.append(rmse)
gb_pred += (sub_pred / 10)
np.mean(rmse_list)1118763.1860099484
2 . LGBMRegressor
lgbm = LGBMRegressor(random_state = 518)
rmse_list = []
lgb_pred = np.zeros((test.shape[0]))
for tr_idx, val_idx in kf.split(X, y) :
tr_x, tr_y = X.iloc[tr_idx], y.iloc[tr_idx]
val_x, val_y = X.iloc[val_idx], y.iloc[val_idx]
lgbm.fit(tr_x, tr_y)
pred = np.expm1([0 if x < 0 else x for x in lgbm.predict(val_x)])
sub_pred = np.expm1([0 if x < 0 else x for x in lgbm.predict(target)])
rmse = np.sqrt(mean_squared_error(val_y, pred))
rmse_list.append(rmse)
lgb_pred += (sub_pred / 10)
np.mean(rmse_list)1203660.01681787
3 . XGBRegressor
xgb = XGBRegressor(random_state = 518)
rmse_list = []
xgb_pred = np.zeros((test.shape[0]))
for tr_idx, val_idx in kf.split(X, y) :
tr_x, tr_y = X.iloc[tr_idx], y.iloc[tr_idx]
val_x, val_y = X.iloc[val_idx], y.iloc[val_idx]
xgb.fit(tr_x, tr_y)
pred = np.expm1([0 if x < 0 else x for x in xgb.predict(val_x)])
sub_pred = np.expm1([0 if x < 0 else x for x in xgb.predict(target)])
rmse = np.sqrt(mean_squared_error(val_y, pred))
rmse_list.append(rmse)
xgb_pred += (sub_pred / 10)
np.mean(rmse_list)1231583.6148945158
4 . CatBoostRegressor
cat = CatBoostRegressor(random_state = 518, silent = True)
rmse_list = []
cat_pred = np.zeros((test.shape[0]))
for tr_idx, val_idx in kf.split(X, y) :
tr_x, tr_y = X.iloc[tr_idx], y.iloc[tr_idx]
val_x, val_y = X.iloc[val_idx], y.iloc[val_idx]
cat.fit(tr_x, tr_y)
pred = np.expm1([0 if x < 0 else x for x in cat.predict(val_x)])
sub_pred = np.expm1([0 if x < 0 else x for x in cat.predict(target)])
rmse = np.sqrt(mean_squared_error(val_y, pred))
rmse_list.append(rmse)
cat_pred += (sub_pred / 10)
np.mean(rmse_list)1117961.732395471
5 . RandomForestRegressor
rf = RandomForestRegressor(random_state = 518)
rmse_list = []
rf_pred = np.zeros((test.shape[0]))
for tr_idx, val_idx in kf.split(X, y) :
tr_x, tr_y = X.iloc[tr_idx], y.iloc[tr_idx]
val_x, val_y = X.iloc[val_idx], y.iloc[val_idx]
rf.fit(tr_x, tr_y)
pred = np.expm1([0 if x < 0 else x for x in rf.predict(val_x)])
sub_pred = np.expm1([0 if x < 0 else x for x in rf.predict(target)])
rmse = np.sqrt(mean_squared_error(val_y, pred))
rmse_list.append(rmse)
rf_pred += (sub_pred / 10)
np.mean(rmse_list)881899.9185985869
최종 예측 결과 블랜딩
submission['box_off_num'] = (xgb_pred + cat_pred + lgb_pred + rf_pred + gb_pred) / 5submission.sort_values(by = 'box_off_num')
코드는 https://dacon.io/competitions/open/235536/codeshare/2721?page=1&dtype=recent 를 참고했다.
score : 493643.24145 / 그냥 한번 끄적여봅니다....
[문화] 영화 관객수 예측 모델 개발
dacon.io
'공부하는 습관을 들이자' 카테고리의 다른 글
| #공부일지 1_1. Introduction to Machine Learning in Production (Coursera) (0) | 2022.11.16 |
|---|---|
| XGBoost vs Randomforest (0) | 2022.06.29 |
| [Dacon study] 2. 타이타닉 생존자 예측 (0) | 2022.02.19 |


