
저에게는 이번 미션을 받고 설렘 반 걱정 반이였습니다
아무래도 처음 주어진 찐 미션이라고 생각하다보니 좋은 주제를 선정하고 싶었습니다.
그런데 데이터를 찾는 것부터가 쉽지 않더라구요..!
어떤 활동이던 데이터를 확보하고 주제를 정하는 것이 난관인 것 같습니다 하하핳..
그래서 저만의 데이터 선정 기준을 정하고 데이터를 고르다보니 더 수월하게 골랐습니다!

1. 데이터 선정 기준
첫째, 자신이 흥미로운 데이터를 선택할 것.
처음 데이터 분석을 시작할 때, 어렵기도 하고 관련 지식이 부족한 경우 데이터 자체를 이해하기 어려웠던 것 같아요. 그래서 관련 지식은 부족하더라도 '재밌고 흥미로운 데이터'를 선택하면 즐겁게 도전할 수 있을거라고 생각했습니다!
둘째, 친숙한 데이터를 선택할 것.
저는 최근 전공에서 들은 과목 중 '시계열 분석'을 수강했습니다. 시계열 분석에서 대표적인 예로 'Amtrak Ridership'으로 프로젝트를 진행했었는데요. 이처럼 실제로 배웠던 이론을 활용할 수 있는 데이터를 쓰면 복습도 되고 실습하는 느낌으로다가.. ㅎㅎ 그리고 무엇보다도 시계열이 저에게는 잘 맞는(?) 과목이였습니다 ㅎㅎ 그래서 저는 시계열 분석을 할 수 있는 데이터셋을 선정하였습니다. (학점은 망... ㅠㅠ)
셋째. 오픈 소스가 많은 데이터를 선택하자!
데이터를 분석하다보면 검색도 하고 책도 찾고.. 부족한 부분이 무엇인지 찾기 위해 구글링을 많이 하는 것 같아요..! (저만 그런거 아니죠 ???)
그래서 데이터 분석을 공부하는 이 시점에서는 구글링이 쉬운! 분석 코드가 많이 있는! 데이터셋을 선택하면 제가 몰랐던 부분이나 더 나은 분석을 하셨던 전문가분들의 글을 보며 도움을 받아 좀 더 쉽게 할 수 있다고 생각합니다!
그래서 데이터 뭐 쓸건데 ?
저는 세 가지 기준에 맞는 주제를 찾던 중
캐글(kaggle)에서 제공된 '제 2차 세계대전 날씨데이터'를 활용하기로 했습니다!
정확한 데이터명은 Weather Conditions in World War Two 로 kaggle에서 제공하는 데이터셋입니다.
잠깐! 세계대전이랑 날씨랑 무슨 상관이냐구요??
날씨는 전장(Battle Field)를 지배한다
이 말이 있을 정도로 날씨가 전쟁에 있어 중요하다고 합니다! + 세계대전과 날씨의 연관성이 궁금하신 분은 위 링크를 한 번 보셔도 좋을 것 같습니다 :)


2. 데이터 : Weather Conditions in World War Two
2.1 데이터 배경
Context & Acknowledgements
Aerial Bombing Operations of World War Two dataset (2차 세계 대전의 공중 폭격 작전 데이터 셋)를 탐색하면서 악천후로 인해 D-DAY가 연기되었다고 합니다.
이를 상기하며 폭격 작전 데이터 세트의 임무와 비교하기 위해 해당 기간의 기상을 보고하려고 하는데,
기상을 예측한다면 수월하게 진행할 수 있기에 예측을 하고자 합니다.
데이터는 미국 국립해양대기청(https://www.kaggle.com/noaa)
국립환경정보센터 웹사이트에서 가져왔습니다.
2.2 데이터 설명
Description
데이터는 총 2개의 csv 파일로 이루어져 있으며
1. 날씨 관측 위치에 관한 파일과 2. 날짜에 따라 관측된 파일로 나뉩니다.
아래와 같은 컬럼이 존재하는데요..! 영어라 거부감이 들긴 하지만 읽어보면 별게 아니더라구요. 그래도 이해를 빠르게 하기 위해 번역해 놓았습니다 :)
- Weather station location:
- WBAN: Weather Station Number
- NAME: Weather Station Name
- STATE/COUNTRY ID: Location
- LAT / Latitude: Latitude as a string / number
- LON / Longitude: Longitude as a string / number
- ELEV : Note that an elevation of 9999 means unknown
- Weather:
- STA: Weather Station
- Date: Self-explantory
- Max Temp: Max temperature
- MeanTemp: Mean temperature
- Min Temp: Min temperature
- Weather station location:
- WBAN: 관측 장소 코드
- NAME: 관측 장소 이름 (Seoul 등)
- STATE/COUNTRY ID: 주/나라 ID
- LAT / Latitude: 위도
- LON / Longitude: 경도
- ELEV : 고도
- Weather:
- STA: 관측 장소 코드
- Date: 날짜
- Max Temp: 최대 기온
- MeanTemp: 평균 기온
- Min Temp: 최소 기온
주제는 '시계열분석을 이용한 날씨(기온) 예측'입니다.
3. 기법 소개
저는 MA, EWMA 모델 중 하나를 활용해서 진행하고자 합니다.
1. MA( 이동평균) 이란 ?
일부 데이터에 많은 비중을 두고 계산을 하는 것으로 연속된 숫자에 따라 계산해서 이후를 예측하는 방법입니다.
2. EWMA (지수가중이동평균) 이란?
변동성을 계산할 때 한 시점 전의 변동성을 고려해서 최근의 변동치에 가중치를 더 두어서 계산하는 방법입니다.
둘 다 시계열 특성을 고려한 모델이라고 보시면 되는데요. 이외에도 ARIMA, WMA 등 여러 시계열 모델이 있으니, 아래 Brightics Studio에서 참고하시면 될 것 같습니다 :)
https://www.brightics.ai/kr/docs/ai/manual/tutorial/b19f13b94cc87c33.html#aba1f64067b2b96e
Brightics Studio 1.1 Tutorial
www.brightics.ai
4. 본격적인 시작!
초기 데이터 셋입니다. 저는 많은 장소 중 Seoul에서의 단순히 온도만을 이용해서 예측하려고 합니다.
그래서 서울과 관련된 데이터만 따로 빼냈습니다. (STA :43201 -> Seoul)
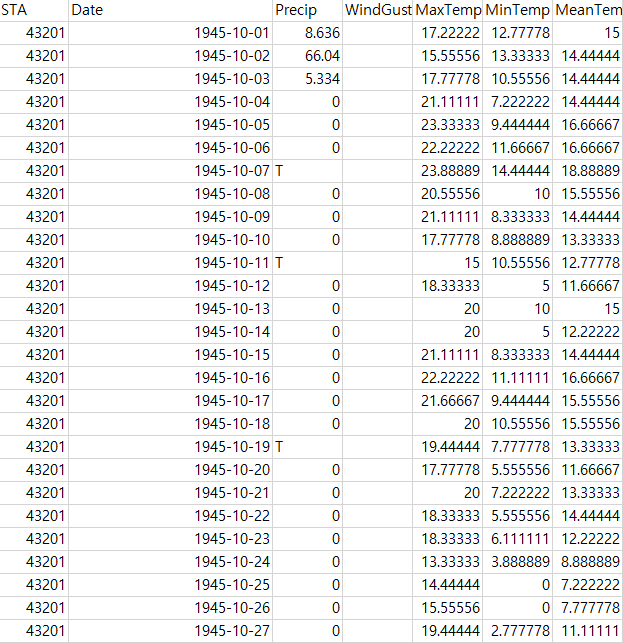
1. Load
brightics에서 데이터를 'Load' 해줍니다.
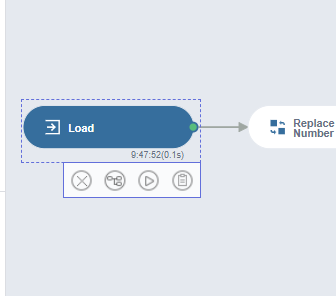
데이터 플로에서 Load 클릭!
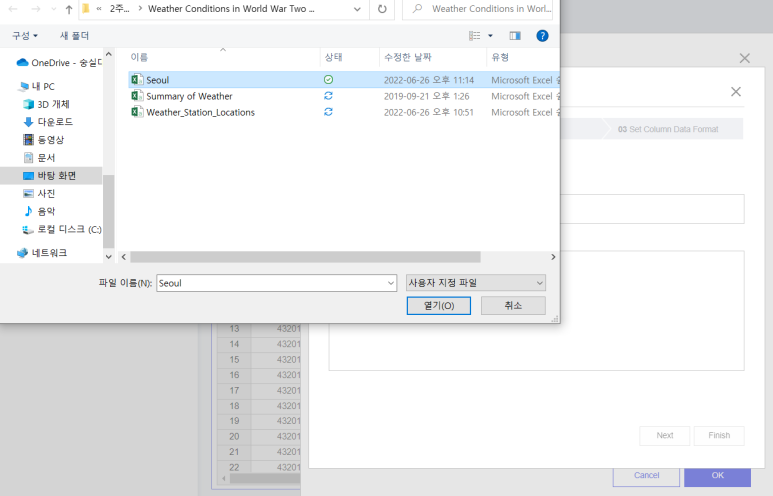
로컬에서 지정된 파일을 불러오면 됩니다.
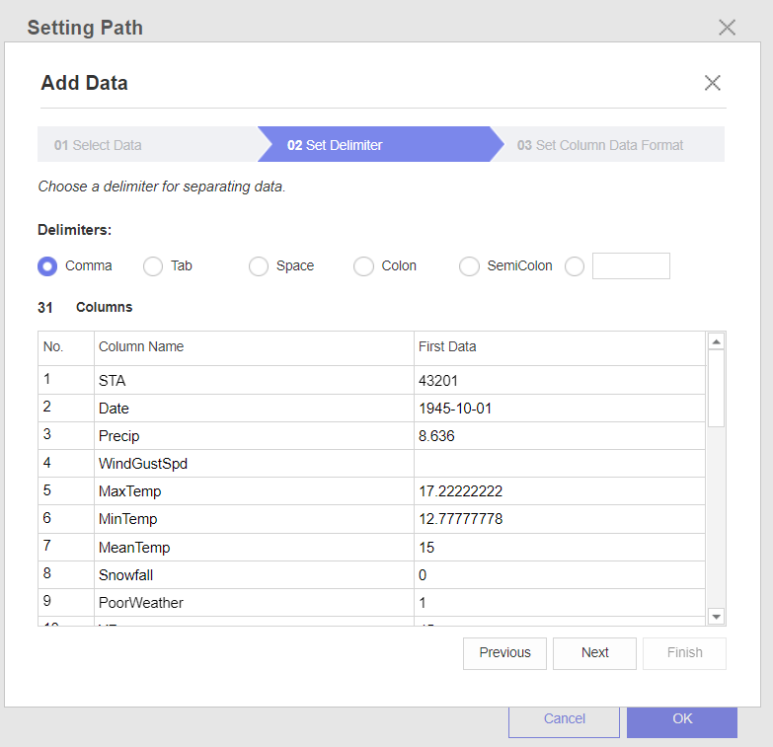
Delimiters는 데이터를 나누는 방식입니다! csv 파일마다 형식이 다른데,
저는 Comma형식이기에 Comma(쉼표)를 클릭하고 Next를 눌러줍니다.
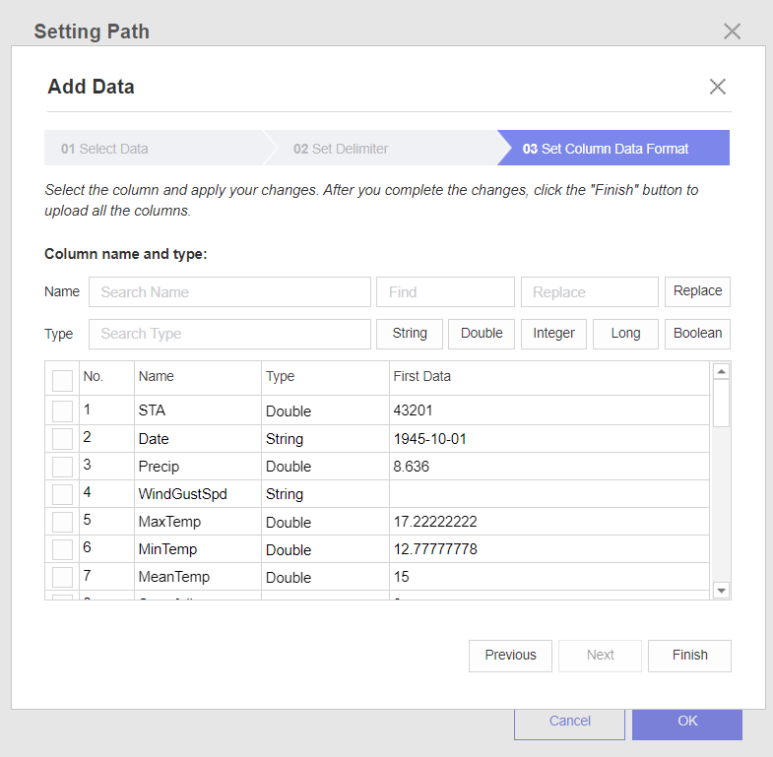
데이터의 Name과 Type, First Data를 확인하며 오류가 있는지 확인해주는 작업입니다.
열 이름에 오류가 생기는 경우도 있어, 수정해주는 작업을 해줘야 합니다!
( 컬럼명으로는 알파벳, 숫자, '_'만 사용 가능합니다.)
2. Replace Missing Number
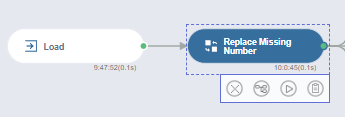
왼쪽은 로드했던 데이터, 오른쪽은 결측치를 제거해준 데이터입니다!
저는 date와 temp에는 결측치가 없지만 혹시 모르니 한번 해줬습니다 :)
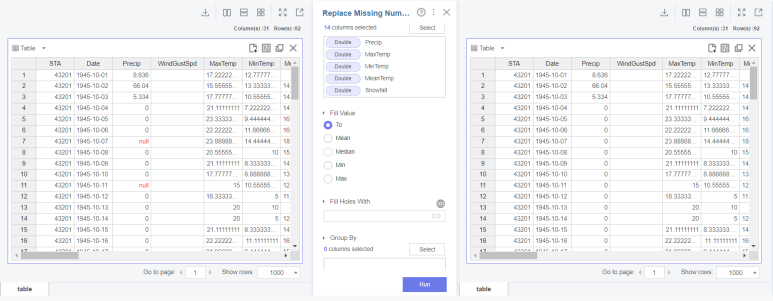
자세히 보면 빨간 박스에서 가운데를 누르면 table 뿐만 아니라 시각화 자료를 제공해줍니다.
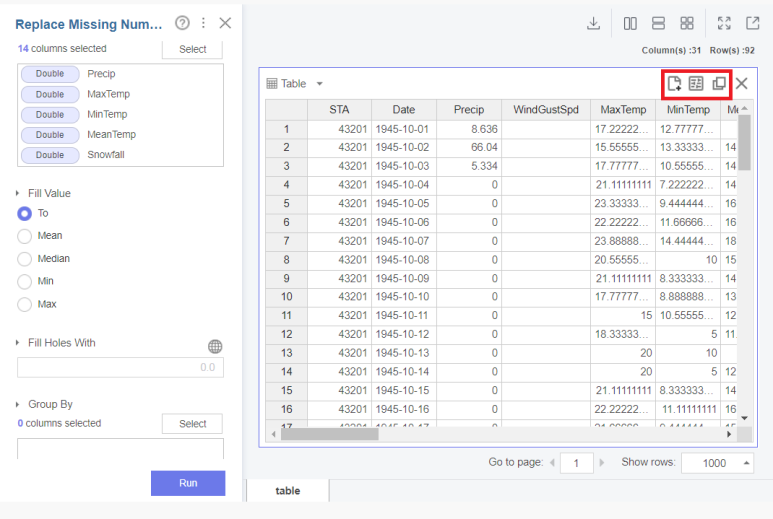
저는 Line으로 x축은 Date, Y축은 Max/Mean/Min Temp로 설정하고 봤습니다.
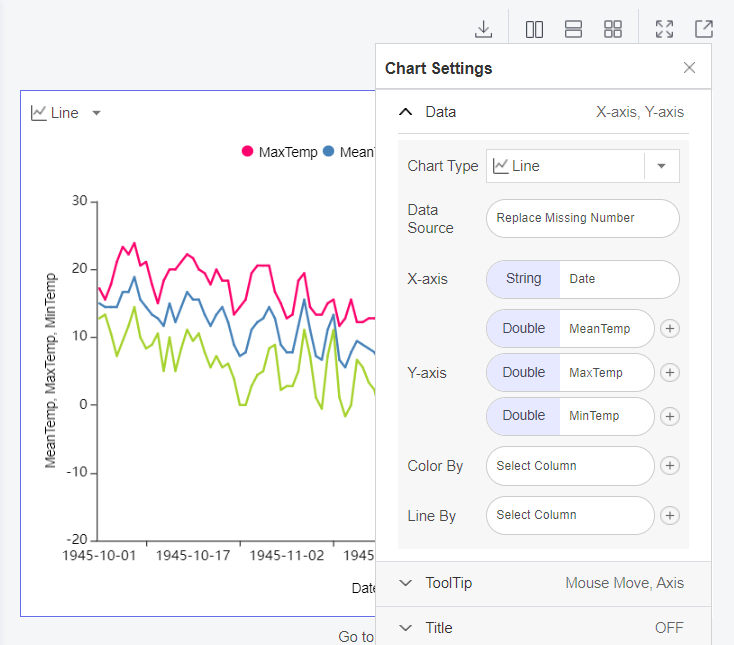
다양한 시각화자료로 활용해보세요!
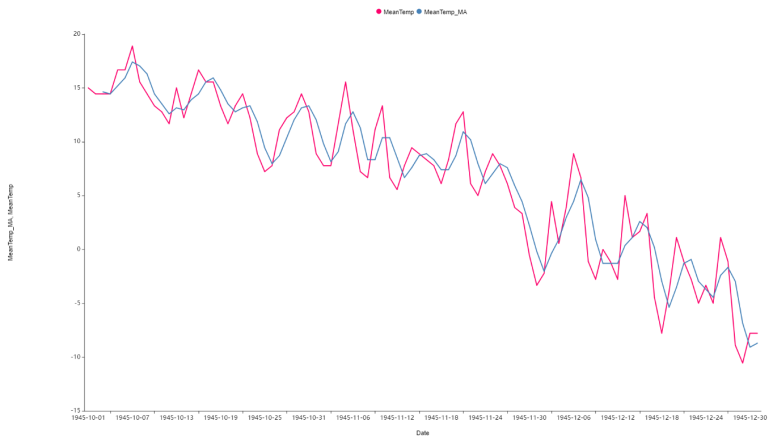
아래 Line을 보시면 MeanTemp를 기준으로 우하향하는 그래프가 그려집니다.
아무래도 가을에서 겨울로 넘어가는 시기이기에 추워지기 때문에 온도가 낮아지는 것을 볼 수 있습니다.
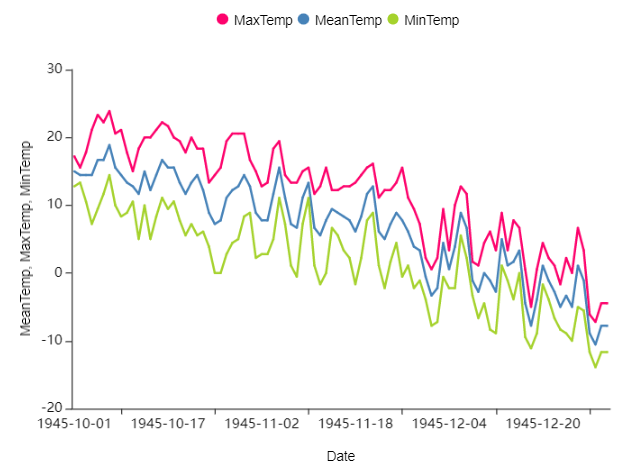
brightics studio 시각화 이쁘다...!!
3. Unit Root Test
시계열 특성을 분석하기 위해서는 '단위근검정' (unit root test)를 해줘야 합니다!
정상적인 시계열 데이터의 경우 이 단위근검정을 잊고 모델을 돌리는 경우가 많은데
'정상성'임을 증명하기 위해서는
시계열에서 꼭! 필요한 존재라는 것을 알아두셨으면 좋겠습니다 :)
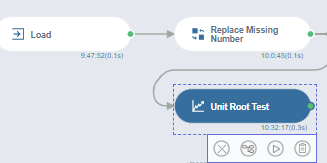
Unit Root Test를 클릭!
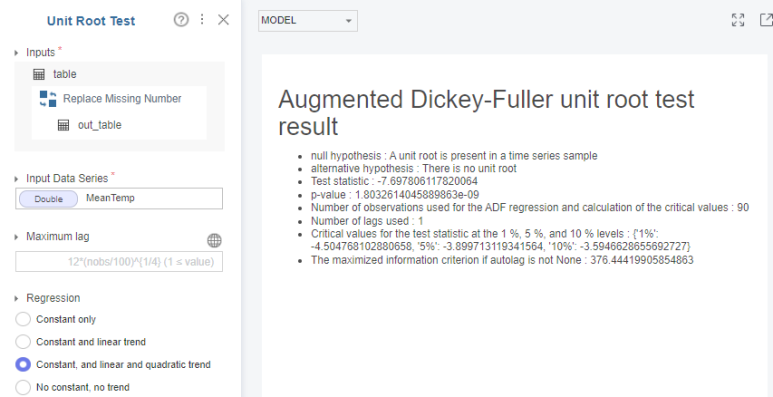
Regression에서 constant인지 linear trend인지 등에 따라 단위근 검정을 합니다.
어렵고 따라오기 벅찬 내용이죠? ㅠㅠ 그래도 차근차근 어떤 내용인지 보게 된다면 금방 이해하실거에요!
p-value가 1보다 큰 높은 수치로 보이므로, 차분의 필요성이 심각하게 느껴집니다..!!
뒤에 보니 e-09로 약 1.8e-09이네요 😂
그러다보니 p-value가 굉장히 작은 값으로
귀무가설을 기각하여 주어진 시계열 데이터가 정상성을 만족한다고 볼 수 있습니다 :)
이후가 궁금하시다면.. 다음 포스팅을 기대해주세요~!!
4. Moving Average
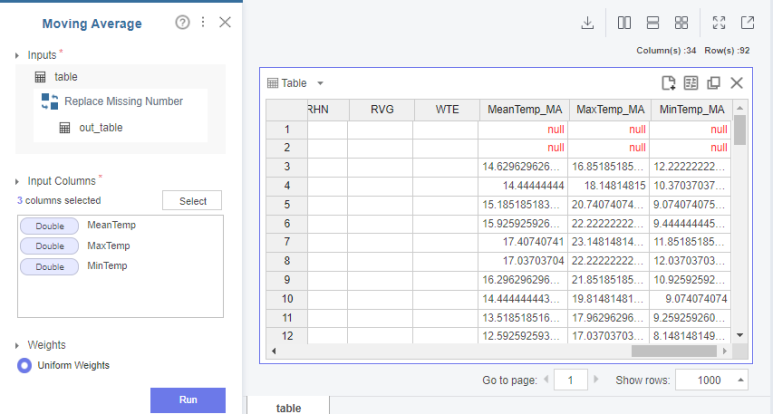
moving average를 눌러 이동평균 모델을 생성한다.
Input Columns에는 MeanTemp,MaxTemp,MinTemp를,
Weights는 Uniform Weight( 동 가중치 부여),
Window Size는 3,
Mode는 Past Values Only로 진행하였습니다.
보시면 처음 2행은 null값이 뜨는 것 보이시죠? window size를 3으로 지정했기 때문이에요..!
(그렇다면! window size =5 면? null값이 4개가 뜰겁니다!)
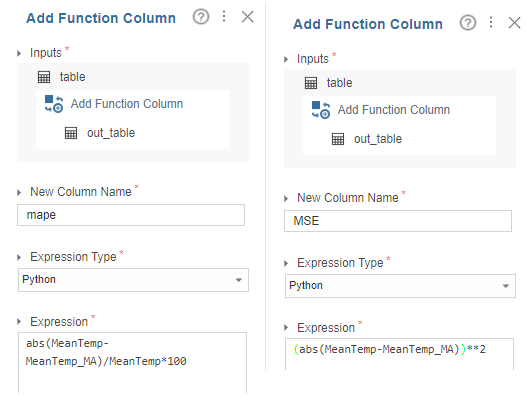
5. Add Function Column
평균 기온과 MA를 사용했을 때의 기온을 비교하기 위해 검증 지표로 MAPE와 MSE를 사용했습니다.
생각해보면, MeanTemp가 0이 나오는 지점도 있기에 MAPE는 의미가 없어보이네요.
그래도 이러한 시행오차를 겪으면서 검증 지표를 정하는데 신중해야한다는 의미로... 집어 넣었습니다 ㅎㅎ
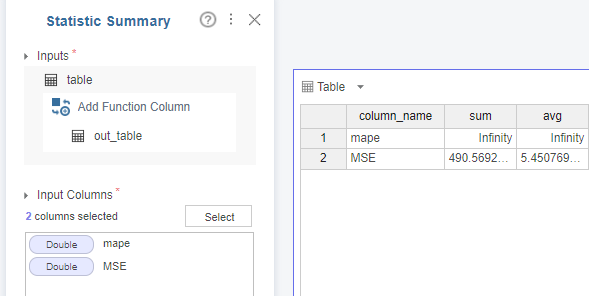
6. Statistic Summary
mape와 mse를 columns으로 하여 합계와 평균을 구했습니다.
mape는 아까 말한 0이라는 이유로 infinity가... (좌절..)
mse의 경우, 평균이 5.45가 나오는 것을 볼 수 있죠?
참고 :MSE, MAE, RMSE, RMSLE 등 평가 지표는 0에 가까울수록 좋답니다!
MeanTemp 와 MA를 적용한 MeanTemp를 간단하게 시각화하였습니다 :)
시계열 분석의 대략적인 플로우를 보기 위해서 간단하게 진행하였습니다.
이어지는 다음 포스팅도 업로드한 데이터
(Weather Conditions in World War Two) 로 진행할 예정입니다.
꼭 기대해주시고 앞으로 저의 활동도 지켜봐주세요! ㅎㅎ
brightics 서포터즈 포스팅 : https://blog.naver.com/dudtjr4915/222791865572
Brightics studio를 이용하여 MA와 EWMA 모델을 사용한 튜토리얼입니다.
https://www.brightics.ai/kr/docs/ai/manual/tutorial/#42e0fc35f6c8fd4d
Brightics ML v3.9 Tutorial
www.brightics.ai
본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
'가치를 창출하는 데이터 분석 > Brightics AI 데이터 분석' 카테고리의 다른 글
| [삼성 SDS Brightics]# 02-3. 개인프로젝트(3) Kaggle 평균 기온 예측하기 - 시계열 분석 (ARIMA / Hot-Winters) (0) | 2022.07.13 |
|---|---|
| [삼성 SDS Brightics]# 02-2. 개인프로젝트(2) Kaggle 평균 기온 예측하기 - 시계열 분석 (MA / EWMA) (0) | 2022.07.05 |
| [삼성 SDS Brightics] #02. 서포터즈 3기 발대식 후기 (0) | 2022.06.28 |
| [삼성 SDS Brightics] #00. 서포터즈 3기 지원부터 합격까지 (0) | 2022.06.25 |
| [삼성 SDS Brightics] #01. Brightics AI 설치 및 체험 리뷰 (0) | 2022.06.21 |



