CNN-LSTM 사용하기에 앞서 PCA를 진행해주었다.
PCA 함수 생성
compute_pca 함수를 만들어,
- covariance 행렬을 계산
- covariance matrix에서 eignvector와 eigenvalue를 계산
- eigenvalue를 오름차순으로 sort
- highest 에서 lowest로 종렬
- eigen vector를 내림차순으로 sort
- n개의 eigenvector를 선택 후 배열
- eigenvector의 transpose를 곱하여 데이터를 변환
def compute_pca(X: np.ndarray, n_components: int=2) -> np.ndarray:
X_demeaned = X - X.mean(axis=0)
covariance_matrix = np.cov(X_demeaned, rowvar=False)
eigen_vals, eigen_vecs = np.linalg.eigh(covariance_matrix)
idx_sorted = np.argsort(eigen_vals)
idx_sorted_decreasing = list(reversed(idx_sorted))
eigen_vals_sorted = eigen_vals[idx_sorted_decreasing]
eigen_vecs_sorted = eigen_vecs[:, idx_sorted_decreasing]
eigen_vecs_subset = eigen_vecs_sorted[:, :n_components]
X_reduced = np.dot(eigen_vecs_subset.T, X_demeaned.T).T
return X_reducedLabelEncoder() 이후 shape을 본 뒤 패딩을 시켜준다. (pad_sequences 사용)
이 후 임베딩 행렬의 크기를 확인.
embedding_matrix = np.zeros((vocab_size, 100))
print('임베딩 행렬의 크기(shape) :',np.shape(embedding_matrix))
100개인 임베일 shape를 50으로 PCA 시행.
X = embedding_matrix
X_reduced = compute_pca(X, n_components=50)CNN-LSTM 모델 생성
Embedding 시킨 모델에 Conv1D를 2곂 쌓고, LSTM을 2곂 쌓아 모델을 구축 후, Flatten으로 1차원으로 만들어준다.
마지막을 softmax를 통해 Dense를 넣어주면 끝. (lstm 사용..)
def build_cnn_lstm(recurrent_dropout = 0.5,dropout=0.5,):
with tf.device('/gpu:0'):
model = Sequential()
model.add(Input(shape=(max_len,)))
e = Embedding(vocab_size,output_dim =50, weights=[X_reduced], input_length=max_len, trainable=False)
model.add(e)
model.add(Conv1D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(dropout))
model.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(256, recurrent_dropout=recurrent_dropout,activation='tanh',kernel_initializer="he_normal",unroll=True,return_sequences=True))
model.add(Dropout(dropout))
model.add(LSTM(512, recurrent_dropout=recurrent_dropout,activation='tanh',kernel_initializer="he_normal",unroll=True))
model.add(Dropout(dropout))
model.add(Flatten())
model.add(Dense(y_train.shape[1], activation='softmax'))
# adam = tf.keras.optimizers.Adam(learning_rate = 1e-5)
return model전에 gridsearch사용으로 Adam과 learning_rate가 8.382620250945622e-05 일 때 Accuracy가 최대가 되어 그대로 사용해준다. (정작 3일동안 모델 5개를 돌렸다.. 한번 돌릴 때 약 12시간 정도..>?)
optimizer = tf.keras.optimizers.Adam(learning_rate = 8.382620250945622e-05)
for tri, vai in cv.split(X_train):
model = build_cnn_lstm2()
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
callbacks = [EarlyStopping(monitor='val_loss', patience=5)]
history = model.fit(X_train[tri], y_train[tri],
validation_data=(X_train[vai], y_train[vai]),
epochs=40,callbacks=callbacks,
batch_size = 106, verbose=1)
models.append(model)
scores.append(history.history["accuracy"])
if is_holdout:
break

약 accuracy가 87.01로 나왔고.. 약간 아쉽지만, 이로써 통계청 활용대회가 끝이났다.
(이 모델도 약 9시간은 돌아간 듯.. 하다)
아쉬운 점은
모델의 구성을 더 세밀하고 탄탄히 쌓아야 한다는 점.
자연어 토큰화 처리할 때, EDA를 더 정교하게 해야할 점.
이 둘을 높이면.. Accuracy가 더 높아지지 않을까 싶다. loss는 훨 적어졌었는데.. 이 모델에서 약간 높은 값이 나와 놀랐다.

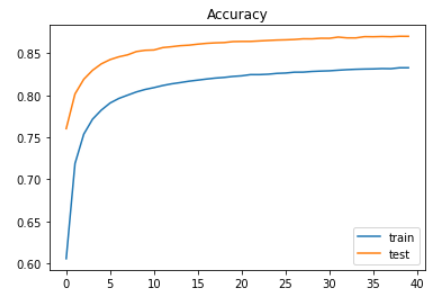
이 전 모델의 loss와 accuracy가 train과 test에서 더 높았는데.. 너무 둘이 안붙는다 ..
관련 github code
https://github.com/rootofdata/NLP_AI_Industry_classification.git
GitHub - rootofdata/NLP_AI_Industry_classification
Contribute to rootofdata/NLP_AI_Industry_classification development by creating an account on GitHub.
github.com
'도전 : 더 나은 사람으로 > 텍스트 산업 분류 공모전' 카테고리의 다른 글
| [2022 통계청 공모전] 5. test 및 후기.. (0) | 2022.05.16 |
|---|---|
| [2022 통계청 공모전] 4. modeling with CNN-LSTM (0) | 2022.05.11 |
| [2022 통계청 공모전] 3. embedding_model (0) | 2022.05.09 |
| [2022 통계청 공모전] 2. remove stopwords (불용어 처리) (0) | 2022.05.08 |
| [2022 통계청 공모전] 1. bigword split (0) | 2022.05.06 |


