임베딩까지 마친 set을 CNN-LSTM의 모델을 적용시키는 분류 분석을 진행하였다.
CNN Algorithm
: 차원 축소 단계를 거쳐 이미지를 분류하는 신경망 알고리즘이다.
convolution layer , pooling layer , fully connected layer을 통해 feature 추출.

LSTM(Long Short Term Memory)
RNN에서 발전된 구조로 3개의 gate와 2개의 state가 존재한다.
- Forget Gate : 잊고자 하는 정도. 활성화함수 : sigmoid 함수 (출력값 : 0~1 사이)
- Input Gate : 새로운 입력을 받고자 하는 정도. 활성화함수 : sigmoid 함수 (출력값 : 0~1 사이)
- Output Gate : Cell State 중 어떤 특징을 출력할 지에 대해 결정. 활성화함수 : sigmoid 함수 (출력값 : 0~1 사이)
- Cell state : 메모리 역할. 여러 차원으로 구성 및 각 차원은 특정 정보를 기억. 특징별로 1~3의 gate로 정보를 주고받는다고 볼 수 있다.
- Hidden state : cell state에 tanh함수를 활성화 함수를 적용한 후, cell state 값이 계속 누적시키는 방법이다. 시간이 지날수록 값이 커진다 -> 그레디언트 값도 점차적으로 커진다.

CNN-LSTM
CNN과 LSTM의 성격을 섞은 방법으로 임베딩한 word vector의 리스트를 각각 CNN의 층에 LSTM을 Sequential layer로 쌓아 text vector를 linear decoder로 변환시키는 작업이다.

필요 패키지 불러오기
from gensim.models import word2vec
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import BatchNormalization, Dropout, Conv1D, Activation, MaxPooling2D, Flatten, Dense,LSTM,Embedding
from tensorflow.keras.utils import plot_model
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categoricaltokenizer 패딩을 위해 vocabulary 만들기.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(NLP)
vocab_size = len(tokenizer.word_index) + 1 # 패딩을 고려하여 +1
X_encoded = tokenizer.texts_to_sequences(NLP)
X_encoded를 패딩
X_train = pad_sequences(X_encoded, maxlen=max_len, padding='post')
print('패딩 결과 :')
print(X_train)
print('y_train numclass',y_train.shape)
embedding_matrix = np.zeros((vocab_size, 100))
print('임베딩 행렬의 크기(shape) :',np.shape(embedding_matrix))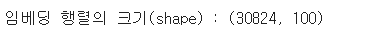
임베딩 벡터값 찾기
for word, index in tokenizer.word_index.items():
# 단어와 맵핑되는 사전 훈련된 임베딩 벡터값
vector_value = get_vector(word)
if vector_value is not None:
embedding_matrix[index] = vector_value진행 과정
자체적 사전을 만든 뒤, X_encoded를 pad_sequences 함수로 패딩을 시키고, 각 리스트의 단어들이 사전으로 인한 벡터값을 표시하게 된다.
예를 들어 '커피'의 매핑된 행렬을 살펴보겠다.
아래와 같이 100개의 리스트로 된 벡터값들이 숫자로 나열되어있고, word2vec 공간 안에 '커피'가 매핑된 벡터들로 나타낸다.
(100인 이유는 분류를 100개로 할 것이기 때문에...)
print(word2vec_model['커피'])
print('단어 커피의 맵핑된 정수 :', tokenizer.word_index['커피'])단어 커피의 맵핑된 정수 : 41
관련 github code
https://github.com/rootofdata/NLP_AI_Industry_classification.git
GitHub - rootofdata/NLP_AI_Industry_classification
Contribute to rootofdata/NLP_AI_Industry_classification development by creating an account on GitHub.
github.com
'도전 : 더 나은 사람으로 > 텍스트 산업 분류 공모전' 카테고리의 다른 글
| [2022 통계청 공모전] 5. test 및 후기.. (0) | 2022.05.16 |
|---|---|
| [2022 통계청 공모전] 4. CNN-LSTM 사용 (0) | 2022.05.15 |
| [2022 통계청 공모전] 3. embedding_model (0) | 2022.05.09 |
| [2022 통계청 공모전] 2. remove stopwords (불용어 처리) (0) | 2022.05.08 |
| [2022 통계청 공모전] 1. bigword split (0) | 2022.05.06 |


