
optuna는 2022 동계 인턴십을 진행하는 와중, GridsearchCV 등을 탐색하다 발견한 automl의 소프트웨어 프레임워크의 일종이다. 최근 뜨기 시작한 automl의 발전하는 단계 중 일환으로 생각하고 있고, 이번에 사용해보기로 하면서 optuna에 대해 공부를 해봤다.
https://optuna.readthedocs.io/en/stable/
Optuna: A hyperparameter optimization framework — Optuna 2.10.0 documentation
Optuna: A hyperparameter optimization framework Optuna is an automatic hyperparameter optimization software framework, particularly designed for machine learning. It features an imperative, define-by-run style user API. Thanks to our define-by-run API, the
optuna.readthedocs.io
optuna는 머신러닝을 위해 설계된 자동 하이퍼파라미터 최적화 소프트웨어 프레임워크이다.
이는 실행에 따라 정의되는 명령형 사용자 API를 제공하며 실행별 정의 API 덕분에 Optuna로 작성된 코드는 높은 모듈성을 누리고 Optuna 사용자는 하이퍼파라미터에 대한 검색 공간을 동적으로 구성할 수 있다.
Key Features
Optuna에는 다음과 같은 최신 기능이 있다.
Lightweight, versatile, and platform agnostic architecture
- 간단한 설치와 코드로 다양한 작업을 처리한다.
pythonic search spaces
- 조건문 및 루프를 포함한 친숙한 python 구문을 사용하여 검색 공간을 정의할 수 있다.
Efficient optimization algorithms
- 매개변수를 샘플링하고 시도를 효율적으로 정리하기 위한 최첨단 알고리즘을 채택한다.
Easy paralleization
- 코드를 거의 변경하지 않고 수십개에서 수백개의 작업을 확장할 수 있다.
Quick visualization
- 다양한 플로팅 기능에서 최적화 기록을 검사한다.
Basic Concepts
Study: optimization based on an objective function
Trial: a single execution of the objective function
# Define an objective function to be minimized.
def objective(trial):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial.suggest_categorical('classifier', ['SVR', 'RandomForest'])
if regressor_name == 'SVR':
svr_c = trial.suggest_float('svr_c', 1e-10, 1e10, log=True)
regressor_obj = sklearn.svm.SVR(C=svr_c)
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 32)
regressor_obj = sklearn.ensemble.RandomForestRegressor(max_depth=rf_max_depth)
X, y = sklearn.datasets.load_boston(return_X_y=True)
X_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X, y, random_state=0)
regressor_obj.fit(X_train, y_train)
y_pred = regressor_obj.predict(X_val)
error = sklearn.metrics.mean_squared_error(y_val, y_pred)
return error # An objective value linked with the Trial object.
study = optuna.create_study() # Create a new study.
study.optimize(objective, n_trials=100) # Invoke optimization of the objective function.
내가 시도한 2022 동계인턴십에서의 코드로는 auc를 예측하는 코드였고, optuna를 이용하여 적중했을 때의 auc 값이 높게 나왔다.
def objective(trial:Trial) -> float:
max_depth = trial.suggest_int('max_depth', 1, 10)
max_leaf_nodes = trial.suggest_int('max_leaf_nodes', 2, 1000)
n_estimators = trial.suggest_int('n_estimators', 100, 500)
rf = RandomForestClassifier(max_depth = max_depth, max_leaf_nodes = max_leaf_nodes,n_estimators = n_estimators,n_jobs=2,random_state=25)
rf.fit(X_train, y_train)
rf_pred = rf.predict_proba(X_test)[:,1]
rf_score = roc_auc_score(y_test,rf_pred)
return rf_scoreRandomforest를 사용했을 때의 auc값 구하기.
sampler = TPESampler(seed=42)
study = optuna.create_study(
study_name="rf_parameter_opt",
direction="maximize",
sampler=sampler,
)
study.optimize(objective, n_trials=10)
print("Best Score:", study.best_value)
print("Best trial:", study.best_trial.params)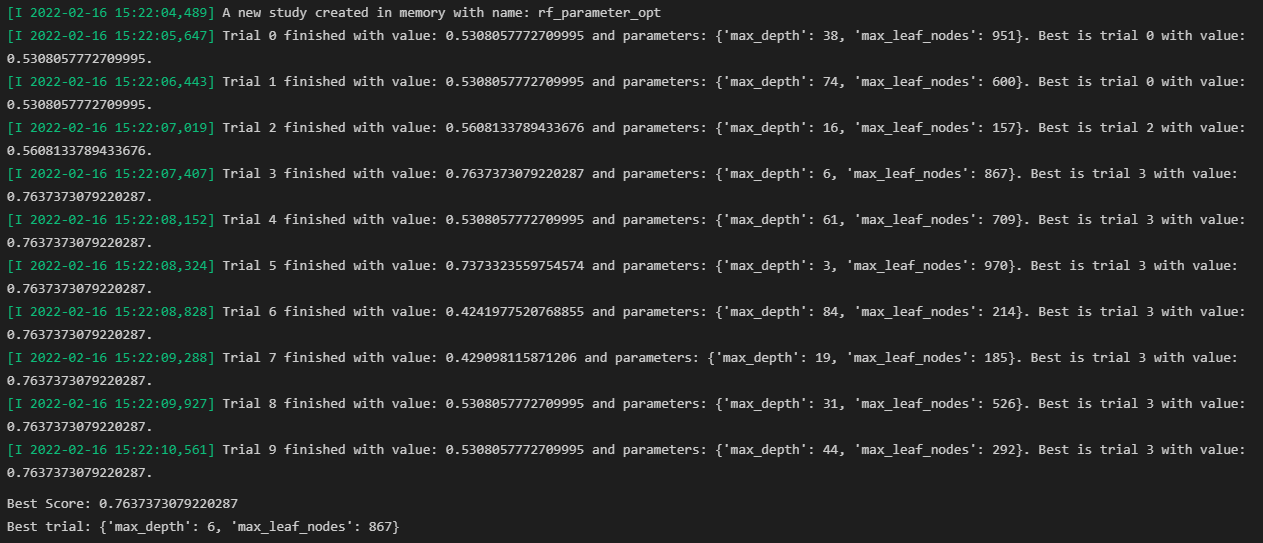
위와 같은 결과로 최적의 파라미터와 그에 맞는 score값을 보여주도록 설정하였다.
'연구 활동 > 폐암 예측 프로젝트' 카테고리의 다른 글
| [2022 동계 인턴십]암예측 최종 (1) | 2022.02.20 |
|---|---|
| [2022 동계 인턴십]암예측 6 - 발표 및 문제점에 대한 피드백 (0) | 2022.02.19 |
| [2022 동계 인턴십]암예측 5 (0) | 2022.02.19 |
| [2022 동계 인턴십] WinSCP 사용법! (0) | 2022.02.19 |
| [2022 동계 인턴십]암예측 4 (0) | 2022.02.16 |



