딥러닝을 이용한 자연어처리 입문 #8-6. (08) 케라스의 함수형 API(Keras Functional API) - (10)다층 퍼셉트론으로 텍스트 분류하기
08) 케라스의 함수형 API(Keras Functional API)
- Sequential API는 복잡한 모델을 만드는데 한계가 있음
- functional API는 입력의 크기(shape)를 명시한 입력층(Input layer)을 모델의 앞단에 정의
1.전결합 피드 포워드 신경망(Fully-connected FFNN)
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
inputs = Input(shape=(10,)) #10개의 입력을 받는 입력층
hidden1 = Dense(64, activation='relu')(inputs)
hidden2 = Dense(64, activation='relu')(hidden1)
output = Dense(1, activation='sigmoid')(hidden2)
model = Model(inputs=inputs, outputs=output) #하나의 모델로 구성
- Input()에 입력의 크기를 정의
- 이전층을 다음층 함수의 입력으로 사용하고, 변수에 할당
- Model()에 입력과 출력을 정의
2) 다중 입력을 받는 모델
두 개의 입력층으로부터 분기되어 진행된 후 마지막에 하나의 출력을 예측하는 모델의 예시
from tensorflow.keras.layers import Input, Dense, concatenate
from tensorflow.keras.models import Model
# 두 개의 입력층을 정의
inputA = Input(shape=(64,))
inputB = Input(shape=(128,))
# 첫번째 입력층으로부터 분기되어 진행되는 인공 신경망을 정의
x = Dense(16, activation="relu")(inputA)
x = Dense(8, activation="relu")(x)
x = Model(inputs=inputA, outputs=x)
# 두번째 입력층으로부터 분기되어 진행되는 인공 신경망을 정의
y = Dense(64, activation="relu")(inputB)
y = Dense(32, activation="relu")(y)
y = Dense(8, activation="relu")(y)
y = Model(inputs=inputB, outputs=y)
# 두개의 인공 신경망의 출력을 연결(concatenate)
result = concatenate([x.output, y.output])
z = Dense(2, activation="relu")(result)
z = Dense(1, activation="linear")(z)
model = Model(inputs=[x.input, y.input], outputs=z)
09) 케라스 서브클래싱 API(Keras Subclassing API)
1. 서브클래싱 API로 구현한 선형 회귀
class LinearRegression(tf.keras.Model):
def __init__(self): #모델의 구조와 동적을 정의하는 생성자 정의
super(LinearRegression, self).__init__()
self.linear_layer = tf.keras.layers.Dense(1, input_dim=1, activation='linear')
def call(self, x): #모델이 예측값을 리턴하는 forward 연산을 진행시키는 함수
y_pred = self.linear_layer(x)
return y_pred
model = LinearRegression()
⇒ functional API로 구현할 수 없는 모델도 구현할 수 있으나 코드가 까다로움
10) 다층 퍼셉트론(MultiLayer Perceptron, MLP)으로 텍스트 분류하기
1. 다층 퍼셉트론(MultiLayer Perceptron, MLP)
- Feed Forward 신경망이 가장 기본적인 형태 (연산 방향이 한 방향)
2. 케라스의 texts_to_matrix() 이해하기
- texts_to_matrix() : 텍스트 데이터를 행렬화 → 4개의 모드
- count : 문서 단어 행렬(Document-Term Matrix, DTM) : 단어 등장 횟수 포함
- binary : 단어의 존재 유무으로만 행렬 표현 (존재하면 1, 아니면 0)
- tfidf : TF-IDF 행렬을 만든다
- freq : 단어의 등장 횟수를 분자로 각 문서의 크기를 분모로 하는 표현 방법
3. 20개 뉴스 그룹(Twenty Newsgroups) 데이터에 대한 이해
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
#훈련/테스트 데이터 불러오기
newsdata = fetch_20newsgroups(subset = 'train')
newsdata_test = fetch_20newsgroups(subset='test', shuffle=True)
train_email = data['email']
train_label = data['target']
test_email = newsdata_test.data
test_label = newsdata_test.target
#전처리
vocab_size = 10000 #최대 단어 개수
num_classes = 20
def prepare_data(train_data, test_data, mode): # 전처리 함수
tokenizer = Tokenizer(num_words = vocab_size) # vocab_size 개수만큼의 단어만 사용
tokenizer.fit_on_texts(train_data)
X_train = tokenizer.texts_to_matrix(train_data, mode=mode) # 샘플 수 × vocab_size 크기의 행렬 생성
X_test = tokenizer.texts_to_matrix(test_data, mode=mode) # 샘플 수 × vocab_size 크기의 행렬 생성
return X_train, X_test, tokenizer.index_word
#texts_to_matrix()를 사용하여 데이터를 행렬화함
X_train, X_test, index_to_word = prepare_data(train_email, test_email, 'binary') # binary 모드로 변환
y_train = to_categorical(train_label, num_classes) # 레이블 원-핫 인코딩
y_test = to_categorical(test_label, num_classes)
4. 다층 퍼셉트론(Multilayer Perceptron, MLP)을 사용하여 텍스트 분류하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
#다중 퍼셉트론 설계
def fit_and_evaluate(X_train, y_train, X_test, y_test):
model = Sequential()
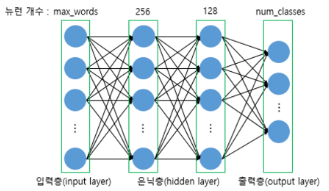
model.add(Dense(256, input_shape=(vocab_size,), activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5)) #과적합 방지를 위한 드롭아웃
model.add(Dense(num_classes, activation='softmax'))
#다중 클래스 분류 문제이므로 활성화 함수는 softmax, 손실함수는 categorical_crossentropy
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=128, epochs=5, verbose=1, validation_split=0.1)
score = model.evaluate(X_test, y_test, batch_size=128, verbose=0)
return score[1]
modes = ['binary', 'count', 'tfidf', 'freq'] # 4개의 모드를 리스트에 저장.
for mode in modes: # 4개의 모드에 대해서 각각 아래의 작업을 반복한다.
X_train, X_test, _ = prepare_data(train_email, test_email, mode) # 모드에 따라서 데이터를 전처리
score = fit_and_evaluate(X_train, y_train, X_test, y_test) # 모델을 훈련하고 평가.
print(mode+' 모드의 테스트 정확도:', score)
binary 모드의 테스트 정확도: 0.8312533 count 모드의 테스트 정확도: 0.8239511 tfidf 모드의 테스트 정확도: 0.8381572 freq 모드의 테스트 정확도: 0.6902549
- 피드 포워드 신경망 언어 모델(Neural Network Language Model, NNLM)
예문 : "what will the fat cat sit on"
-원핫인코딩
what = [1, 0, 0, 0, 0, 0, 0]
will = [0, 1, 0, 0, 0, 0, 0]
the = [0, 0, 1, 0, 0, 0, 0]
fat = [0, 0, 0, 1, 0, 0, 0]
cat = [0, 0, 0, 0, 1, 0, 0]
sit = [0, 0, 0, 0, 0, 1, 0]
on = [0, 0, 0, 0, 0, 0, 1]
-정해진 개수의 단어만 참고함
n=4

- 투사층: 은닉층과 다르게 활성화 함수가 존재하지 않음, 가중치 행렬이 이루어짐

- V(단어 집합의 크기)*M(투사층의 크기) 크기로 만들어짐
- 룩업 테이블: i번째 행을 그대로 읽어오는 것
- 룩업 과정을 거친 후 더 차원이 작은 M차원의 벡터로 맵핑됨 → 임베딩 벡터


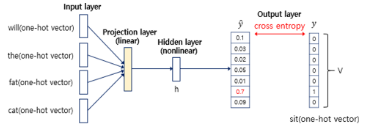
→ sit 을 예측해야 하는 다중 클래스 분류 문제
- NNLM의 이점 : 수많은 문장에서 유사한 단어들은 유사한 임베딩 벡터값을 얻게됨
반응형
'공부하는 습관을 들이자 > Deep Learning (NLP,LLM)' 카테고리의 다른 글
| [딥러닝 자연어처리] 9-2. (05) 양방향 순환 신경망 - (07) 게이트 순환 유닛 (0) | 2023.12.26 |
|---|---|
| [딥러닝 자연어처리] 9-1. (01) 순환 신경망 (Recurrent Neural Network) (0) | 2023.12.25 |
| [딥러닝 자연어처리] 8-5. (6) 기울기 소실과 폭주 - 07) 케라스 훑어보기 (0) | 2023.12.20 |
| [딥러닝 자연어처리] 8-4. (4.) 역전파 이해하기 - (5) 과적합을 막는 방법들 (0) | 2023.12.19 |
| [딥러닝 자연어처리] 8-3. (4) 딥러닝의 학습 방법 (0) | 2023.12.18 |



